Accelerate: データ駆動型 DevOps パート4: ビジネス・アジリティ
2020/10/9 - 読み終える時間: 2 分
Data-Driven DevOps Part 4: Business Agility の翻訳版です。
データ駆動型DevOpsパート4:ビジネス・アジリティ
2020年10月9日
著者: Steve Boone / HCL Software DevOps Head of Product Management
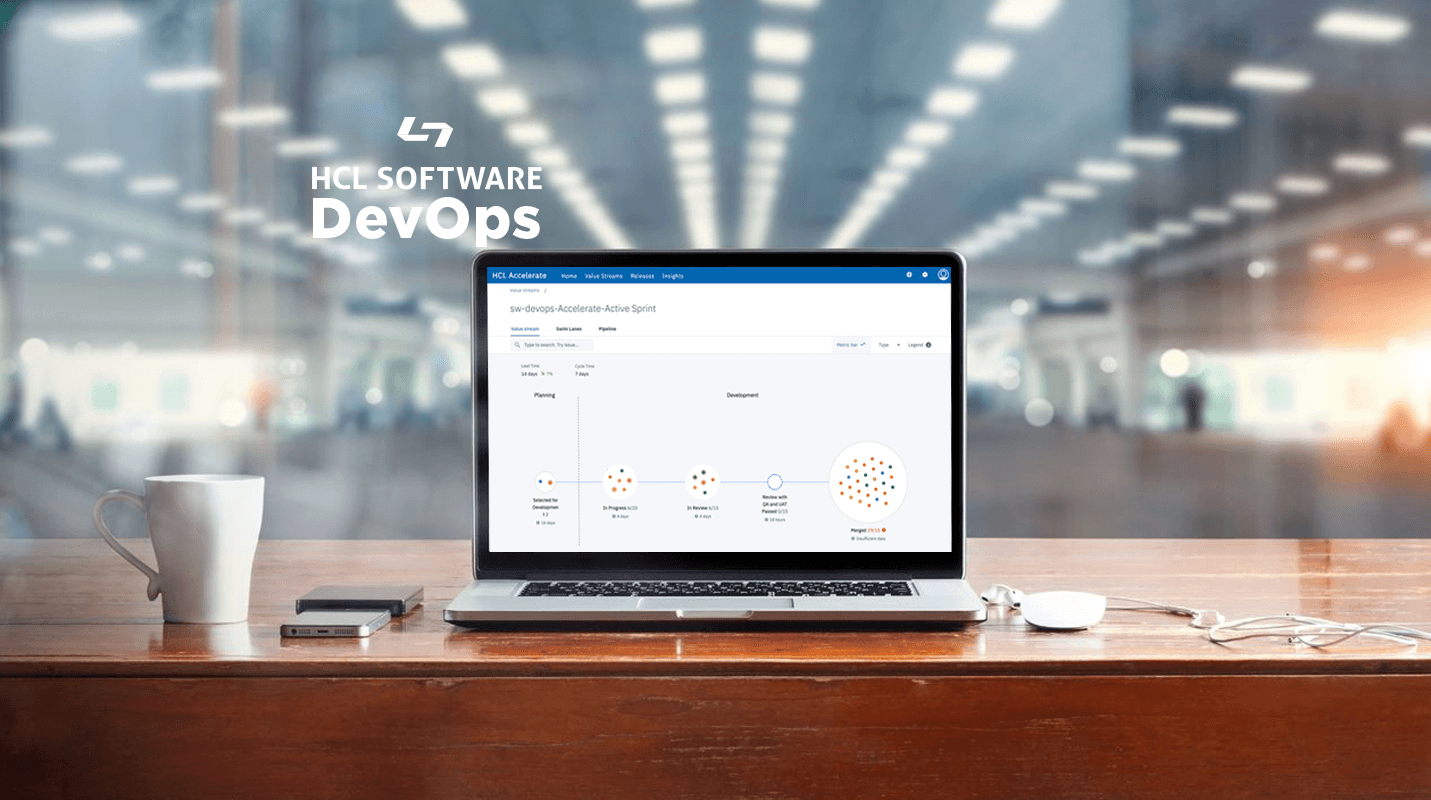
シリーズの過去のパート
- Accelerate: データ駆動型 DevOps パート 1: 序章
- Accelerate: データ駆動型 DevOps パート 2: データ駆動型の文化
- Accelerate: データ駆動型 DevOps パート 3: データを使った追跡と計画
私がウェビナーやブログ記事、プレゼンテーションの中で、ビジネスの俊敏性についてよく話しているのを聞いたことがあると思います。それは、HCL Software DevOps のキャッチフレーズの一部でさえあります。セキュアでデータ駆動型のビジネス・アジリティ。しかし、ビジネス・アジリティとは実際には何を意味し、データ駆動型の DevOps 戦略にどのように適合するのでしょうか?
ビジネス・アジリティとは、ビジネスまたはその構成要素が、安定性を維持するために適応することで変化に迅速に対応する能力のことを指します。この概念は決して新しいものではありません。実際、アジャイル開発のコアとなるアイデアはここから得られます。変化に適応する能力は、アジャイルプロジェクト管理の要であり、アジャイル開発手法の主な利点の一つです。開発チームが時間を有効に使えば、ステークホルダーが求めているものをタイムリーに届けることができる。また、ステークホルダーのニーズが変われば、それに合わせてチームの行動もすぐに変化させることができます。
2020年、企業はコロナウイルスのパンデミックにより、かつてない状況に直面しています。これらの状況は、企業が日々の活動に慣れている方法、特に顧客とのやりとりに大きな混乱をもたらしています。このような荒れた時代を生き抜くためには、データ駆動型のビジネス・アジリティが必要であることは間違いありません。
データ駆動型の DevOps 組織は、何が破壊されているのかを迅速に特定し、コース修正のための迅速で積極的な会話ができるようにすることで、競合他社に対して優位に立っています。多くの個人やビジネス・ユニットが問題の解決策を考え出し、すべての新しいアイデアが優れたものになるわけではなく、また、これらのアイデアの多くが新たな課題を提示することになります。どのようにしてそのすべてを吟味するのか? 問題を修正しすぎたり、修正しきれなかったりした場合、どのようにして認識するのでしょうか?
データがなければ、このプロセスは推測ゲームであり、新しいプロセスのテストに多くの無駄な時間を費やし、失敗する可能性があります。適切なデータがあれば、より早く失敗することができるので、より早く成功にたどり着くことができます。成功している組織は、偉大になるためには失敗しなければならないという考えを受け入れる文化を持って、早く失敗するという考えを受け入れています。失敗を早くして、その失敗を認識すればするほど、失敗はすぐに学習の機会となります。ヘンリー・フォードは、「失敗とは単に、もう一度やり直す機会であり、今回だけはもっと知的に」と言いました。これこそが、まさにデータ駆動型 DevOps の目標なのです。
このシリーズのパート 2 では、ソースコード管理やワークアイテム管理技術に由来する、個々の貢献者によって生成されたデータが、組織全体の文化や、利害関係者への成果物を正確に予測する能力の向上にどのように役立つかについて議論しました。ビジネスの俊敏性については、継続的インテグレーションやデプロイメントソリューションからテストの自動化やセキュリティスキャンの結果に至るまで、さまざまな DevOps テクノロジーから得られるデータに焦点を当てていきます。これらのデータをキャプチャし、可視化し、処理することができる組織は、以下のことが可能であることに気づくことでしょう。
- アイデアから顧客まで、現在のエンドツーエンドのソフトウェア・デリバリー・プロセスをベンチマークする
- 既存または新たに作成されたボトルネックの特定
- 新しいプロセスの変更やアイデアの影響を理解し、迅速に失敗して混乱を回避できるようにします。
究極のフィードバックループと継続的改善
ソフトウェア・デリバリ・パイプラインから送られてくるデータを可視化して分析することで、組織は貴重な「高速フィードバック」ループを実装するという DevOps のアプローチを取ることができます。多くの企業にとって、日々の業務をオーバーホールする機会は、年に一度か二度しかありません。これは単に十分なスピードではありません。文化的にも、私たちは日々向上していくことを受け入れなければなりません。そのためには、まず、現在の業務のベースライン、つまり現在のパフォーマンスのベンチマークを確立する必要があります。そのベンチマークが決まれば、データのライブ表示がリアルタイムのバリュー・ストリームとなり、組織は改善の余地があるところに焦点を当てることができます。
リアルタイム・バリュー・ストリームには、多くの優れた利点があります。最も明白な利点の1つは、特定の作業単位を追跡し、それをスプリント、リリース、チーム、および個々の貢献者に関連付けることができることです。この作業をバリューストリームの特定のステージに結びつけることができるので、作業が行き詰っている場所を簡単に発見することができます。
このような隠れたボトルネックのお気に入りの例の一つは、HCL Software の自社開発チームの一つにありました。このチームは、コードレビューに悩んでいました。彼らは、コードをマージする前に行わなければならないコードレビューのバックログを常に大量に抱えているようでした。バリュー・ストリームのデータを可視化することで、作業が行き詰った段階を正確に見ることができ、納品プロセスにボトルネックを作っていました。彼らはコードレビューを行うことに長けていましたが、システム内のコードレビューを承認する権限を与えられた人が十分にいなかっただけでした。それは取るに足らない利益のように見えるかもしれませんが、私たちのソフトウェア開発プロセス全体に散らばっている無駄のポケットが何十もあります。それらを取り除くことができればできるほど、馬からユニコーンへの移行のための道が開ける可能性が高くなります。
プロセスの変更と混乱
チームが現在の価値の流れを評価し始めると、現在のプロセスを合理化するための多くの創造的な 方法を思いつくでしょう。その中には良いものもあれば悪いものもあるかもしれませんが、重要なのは、チームとビジネスの両方が新しいプロセスの変更の結果を追跡して、スループットの増加があったかどうかを判断することができるということです。これにより、新しいプロセスを導入したことで、実際に高品質のソフトウェアをより早く、より早く提供できるかどうかを知ることができます。
このように大量のデータがあれば、すべてが意見である必要はありません。データは、会話から「私はそう思う」を取り除き、「私たちは知っている」に変えます。個人が「2週間のスプリントから1週間のスプリントに移行してから、私たちの方がうまくいっていると思います」と言うのではなく、データを調べて確かなことを知ることができます。これは、私たちが話していた文化についての対話に戻ってきます。チームが自分たちのプロセスを定義することを信頼しているのであれば、チームが自分たちのミスから学ぶのを助けるツールを提供する必要があります。これは、エンジニアリングチームがスピードを上げすぎて品質が低下することを防ぐと同時に、エンドツーエンドのプロセスが可能な限り堅牢で効率的であることを確認するためのものです。
データ駆動型 DevOps の旅にご参加いただき、ありがとうございました。これまで、データ改善の文化をどのように改善するか、ソフトウェア配信の追跡と計画をより効率的にし、組織にビジネスの俊敏性をもたらし、潜在的な混乱に迅速に対応できるようにするかについて見てきました。次回の記事では、すべてのデータを一堂に集めて、ビジネスの整合性についてこれまでにない可視性を提供することについてお話ししますので、ご期待ください。また、データがどのようにしてリスクを軽減し、組織をガバナンスの自動化への道へと導くのかについてもお話しします。
Accelerrate: データ駆動型 DevOps パート 3: データを使った追跡と計画
2020/10/9 - 読み終える時間: 2 分
Data-Driven DevOps Part 3: Track and Plan with Data の翻訳版です。
データ駆動型 DevOps パート 3: データを使った追跡と計画
2020年10月7日
著者: Steve Boone / HCL Software DevOps Head of Product Management
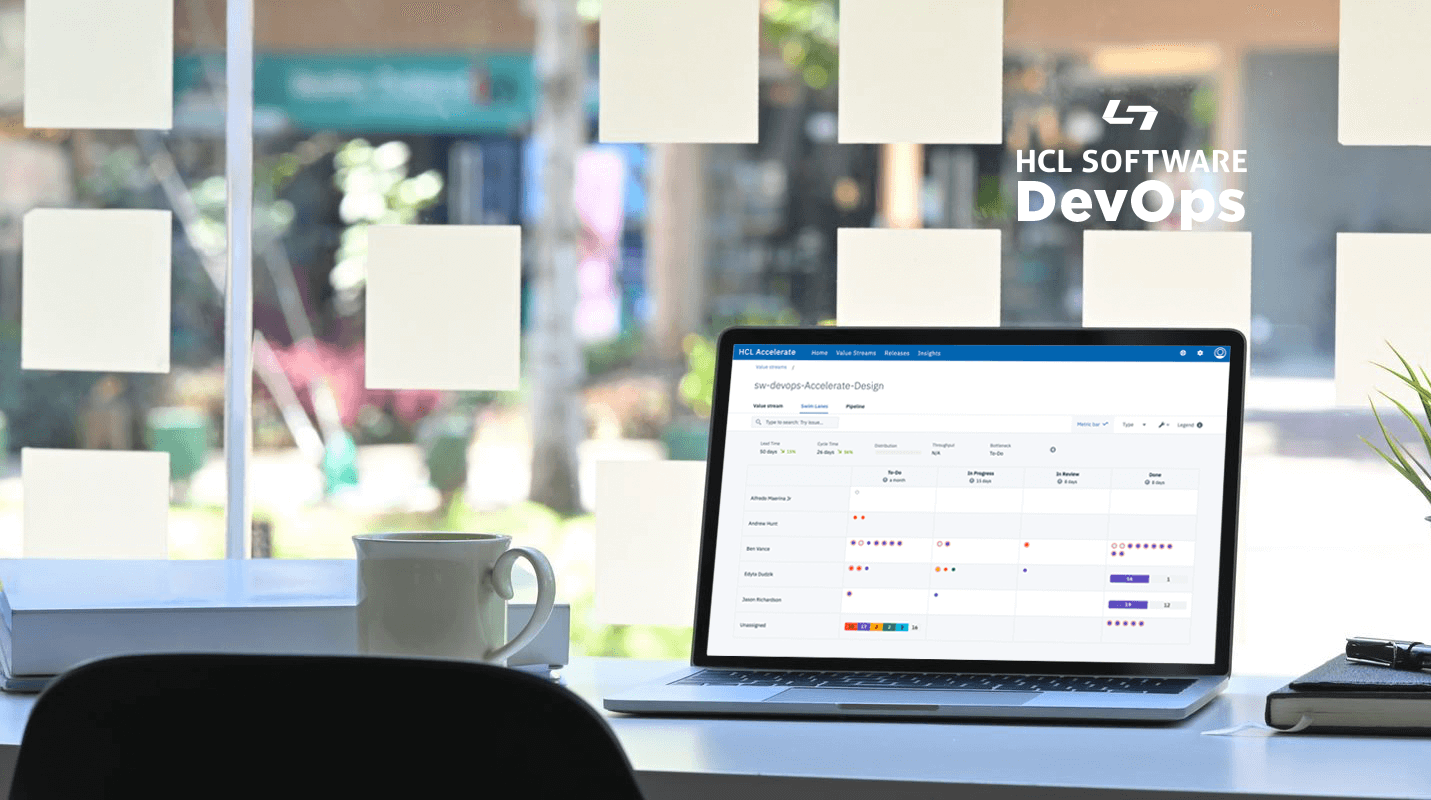
シリーズの過去のパート
応答性の高い、高度にアジャイルな開発組織を持つことに伴う課題は、ビジネス、顧客、自社のチームからの多数の要求を常にこなすことです。これにより、与えられたスプリント内で現実的に達成できる以上の作業を議論し、優先順位をつけなければならなくなります。スクラム、カンバン、エクストリームプログラミングからアダプティブ、ダイナミック、リーンソフトウェア開発に至るまで、チームは何年にもわたって多くの方法論を使ってトラッキングと計画を改善しようとしてきました。それぞれのアプローチは、予測可能でありながらも柔軟性があるという同じ課題に異なるひねりを加えています。
データは、開発チームの追跡と計画の能力において重要な役割を果たすことができます。前回の記事では、データが開発チーム全体のコラボレーションとコミュニケーションをどのように向上させることができるかについて説明しました。具体的には、チームがスプリントごとに作成したデータを分析することで、何がうまくいっていて何がうまくいっていないのかを特定するためのプロセス改善に関する会話が促進されることがわかります。文化を超えて、データ分析には、組織の追跡と計画の能力にいくつかの利点があります。
チームの速度を特定することで計画を改善する
スクラムチームにとって、ベロシティとは、チームが1回のスプリントでどれだけの作業に取り組めるかを示す指標であり、スプリントで配信されたストーリーポイントの数を合計して計算されます。チームのベロシティを知ることは、特定のスプリントやリリースの計画を立てるのに役立つだけでなく、組織全体や顧客とのコミュニケーションを改善するのにも役立ちます。
チームのベロシティを理解することは、意味のある期待値を設定するのに役立ちます。計画されたリリースの数週間前に、納品が予定されていたアイテムのうち、一握りのアイテムが届かないことに気付いたことは何度ありますか?それはいつもガッカリです。透明性を高め、混乱を減らすためには、利害関係者や顧客との間で意味のある現実的な期待値の設定が必要です。そして、この同じ透明性は、個々の貢献者が設定された目標の達成に成功する可能性を高めることになります。
リードタイム、サイクルタイム、スループットなど
組織の正確な予測能力を大幅に向上させることができる指標は、ベロシティだけではありません。リードタイムとサイクルタイムは、開発チーム、プロダクトマネージャ、およびリリースエンジニアが、組織を通じてソフトウェアを提供するのにかかる時間を理解するために追跡する最も一般的な統計量です。この 2 つの指標の違いは微妙です。
-
リードタイムとは、新しいタスクがバックログに表示されてから最終的に「完了」となるまでの期間のことです。多くのチームはリードタイムを定義する別の方法を使用するでしょう。そうでなければ、新しいタスクが優先順位を付けられる前に数ヶ月間バックログに残っている可能性があり、それがリードタイムを膨らませる可能性があります。
-
サイクルタイムとは、誰かがリクエストやタスクの作業を開始した瞬間から始まり、作業が完了するまでの期間を指します。
これらの測定基準はどちらも強力なものです。キャパシティをよりよく理解するのに役立つだけでなく、チームの現在の作業プロセスや、現在のワークフローのボトルネックを示す貴重な情報を提供してくれます。
しかし、リードタイムとサイクルタイムだけでは十分ではありません。これらを単独で解釈した場合、チームが特定のスプリントやリリースでどのような作業を完了できるかについて多くの疑問が残ります。これらの質問に対する答えをよりよく理解するために、スループット、分布、コントリビューターなどのデータ内で見られるさまざまな指標に注目しています。
-
スループットとは、与えられた期間に完了したタスクや作業項目の数のことです。これは、ストーリーポイントを考慮するベロシティとは異なります。
-
ディストリビューションとは、タスク、欠陥、機能など、スプリントのために完了した作業の種類の詳細な内訳です。
-
コントリビューターとは、与えられたスプリントに参加している開発者の数です。10人の開発者で構成されたチームが、常に10人の開発者が貢献しているとは限りません。休暇や病気、そして多くの種類の予定外の作業があるため、この数はかなり一貫性のないものになる可能性があります。
正確に成果物を予測しようとするときには、これらすべての指標を考慮することが重要です。 開発チームのリードタイム、サイクルタイム、ベロシティ、スループット、貢献者の平均数、および典型的な分布を知ることで、作業がいつ完了すべきか、そして最も可能性の高い作業の種類をより正確に把握できます。
リスクの特定
もちろん、どのチームでも時折、何らかの配送の遅延が発生することがあります。このようなシナリオでは、何をリリースの範囲から外すべきか、外すべきではないかについて、組織が計算された情報に基づいた意思決定を行うことが重要です。開発チームのデータを分析することの主な利点の1つは、特定のタスクをビジネス価値に結びつけることができるようになることです。開発用語で言うと、これはエピックス(ビジネス価値)と作業項目(タスク)をリンクさせることを意味します。
このリンクを作成することで、あるビジネス価値のうち、何%が完成しているかを把握し始めることができます。この情報は、リスクを特定し、ステークホルダーや顧客に伝え、意味のある期待値を設定する上で非常に貴重なものです。納品物が抜け落ちたときはいつでも、「なぜこの作業を完了できなかったのか」、「チームはこの納品物の他に何に集中していたのか」など、いくつかの質問が出てくることでしょう。これらの質問に対する答えは、データの中に見つけることができます。進行中の作業が多すぎたのかもしれないし、サポートの問題でチームが脇道にそれてしまい、予定していた作業から遠ざかってしまったのかもしれません。答えが何であれ、データを分析することで、開発チームはより意味のある回顧を行い、プロセスを調整して、同じ間違いが将来発生しないようにすることができます。
データ駆動型の DevOps は非常に強力です。これまでに、コミュニケーションとコラボレーションを改善することで文化を向上させる方法について説明してきましたが、データを活用することで、ビジネス価値の追跡と計画をより効果的に行うための能力を磨くことができる重要な方法をいくつか紹介してきました。次回は、データが組織のビジネス・アジリティ(安定性を維持するために適応することで変化に迅速に対応するビジネスの能力)をどのように向上させることができるかについてお話しします。
HCL Z Asset Optimizer: 製品紹介ビデオ
2020/10/8 - 読み終える時間: ~1 分
HCL Software はメインフレーム関連のソフトウェアも開発、販売しております。HCL Z Asset Optimizer はソフトウェア資産を検出し、ライセンス費用の最適化やライセンス違反回避を可能にするものです。
7分強の製品紹介ビデオを HCL Z Asset Optimizer 製品ページに追加しました。メインフレーム資産管理に課題をお持ちのお客様には是非ご覧いただきたいと思います。
Unica Discover: カスタマーエクスペリエンス戦略の策定
2020/10/8 - 読み終える時間: 2 分
Unica Discover - Formulate Your Customer Experience Strategy の翻訳版です。
Unica Discover: カスタマーエクスペリエンス戦略の策定
2020年10月7日
著者: Simon Warbey / Product Manager | Consultant | Solution Director

私たちは皆、消費者としての日常生活の中で葛藤を経験してきました。その苦労とは、カートに何かを入れても在庫がないことに気付いたり、自分には関係のない商品の提案を受けたりするなど、様々なことが考えられます。これを書いている今、英国最大級の小売銀行のオンラインシステムとモバイルシステムが利用できず、自分の口座を確認したり、振り込みをしたりすることができません。 これらの例はすべて、ユーザー体験に摩擦をもたらし、ブランドの認知度を低下させ、ネガティブな体験を友人や家族と共有したり、ソーシャルメディア上で声を上げたりすることにつながっています。
カスタマーエクスペリエンスとは?
カスタマーエクスペリエンス(CX)とは、顧客がブランドを利用するまでのあらゆる側面(最初に接触してから、幸せで忠実な顧客になるまで)をカバーしています。これが顧客を貴社の製品にリピートさせ、最終的にはブランドの支持者となるための原動力となります。驚くべきカスタマーエクスペリエンスを提供するかどうかは、顧客があなたの店舗で購入した後にメールを送信したり、問題を解決する際に顧客担当者がどれだけ注意を払っているかなど、あらゆるタッチポイントでブランドとしてどのように対話するかにかかっています。
なぜカスタマーエクスペリエンスが重要なのか?
オンデマンドや迅速な配送/配送サービスの台頭により、顧客はより多くのことを期待し、要求するようになりました。顧客は、24時間から 48時間以内に商品を配送するなど、より迅速な対応を求めるようになりました。これはあらゆるところで顧客の期待を高め、最終的にはそれが実現しない場合のフラストレーションの可能性を高めています。これは市場調査にも反映されています。

デジタルエクスペリエンスの専門家の 79%が、自分たちが提供するカスタマーエクスペリエンスを非常に、または非常に高い優先度と評価しています。これらの専門家が重要性を認識していることは素晴らしいことですが、そうでない21%の人もいます。同じ専門家の90%は、ユーザーがなぜそのような行動をとるのかについての深い洞察力が不足していると認めています。2020年末までに、ブランドの主要な差別化要因として、顧客体験が価格や製品を追い越すことになるだろう)。ブランドとして、カスタマーエクスペリエンスの最適化にまだ注力していない場合、これを優先事項としている競合ブランドに顧客を奪われる可能性があることを意味します。
そのような体験を見ることができたらどうでしょうか?そのような体験をした人たちを理解し、ビジネスにどのような影響を与えたかを理解できたらどうでしょうか?その人やオーディエンスを捉え、遭遇した悪い体験を積極的に解決し、顧客のコンバージョンとエンゲージメントを同時に向上させることができたらどうでしょうか?カスタマーインサイトを分析し、アクセスできるようにすることで、これらすべてを実現できます。
カスタマーインサイトとは?
カスタマーインサイトとは、顧客からのフィードバックやその他の情報源から収集した定量的・定性的データを分析し、情報に基づいたデータ駆動型のビジネス上の意思決定を行うことです。その目的は、行動傾向を特定し、マーケティング、販売、その他のサービスの効果を向上させることにあります。誰もがパーソナライズされた体験を楽しんでおり、顧客の洞察力にアクセスすることで、製品が顧客の期待に沿ったものであることが保証されます。しかし、このプロセスを可能にするためには、適切なツールセットを用意する必要があります。
Unica Discover の紹介
Unica Discover を使用するとこれらすべてを実現できます。発生した時点でのユーザー体験を把握し、ユーザーの苦戦を経験したセッションを迅速に特定して痛点を診断することで、ネガティブなユーザー体験を緩和し、マーケティングやリカバリー・キャンペーンを通じてユーザーを特定して積極的にリターゲティングすることができます。
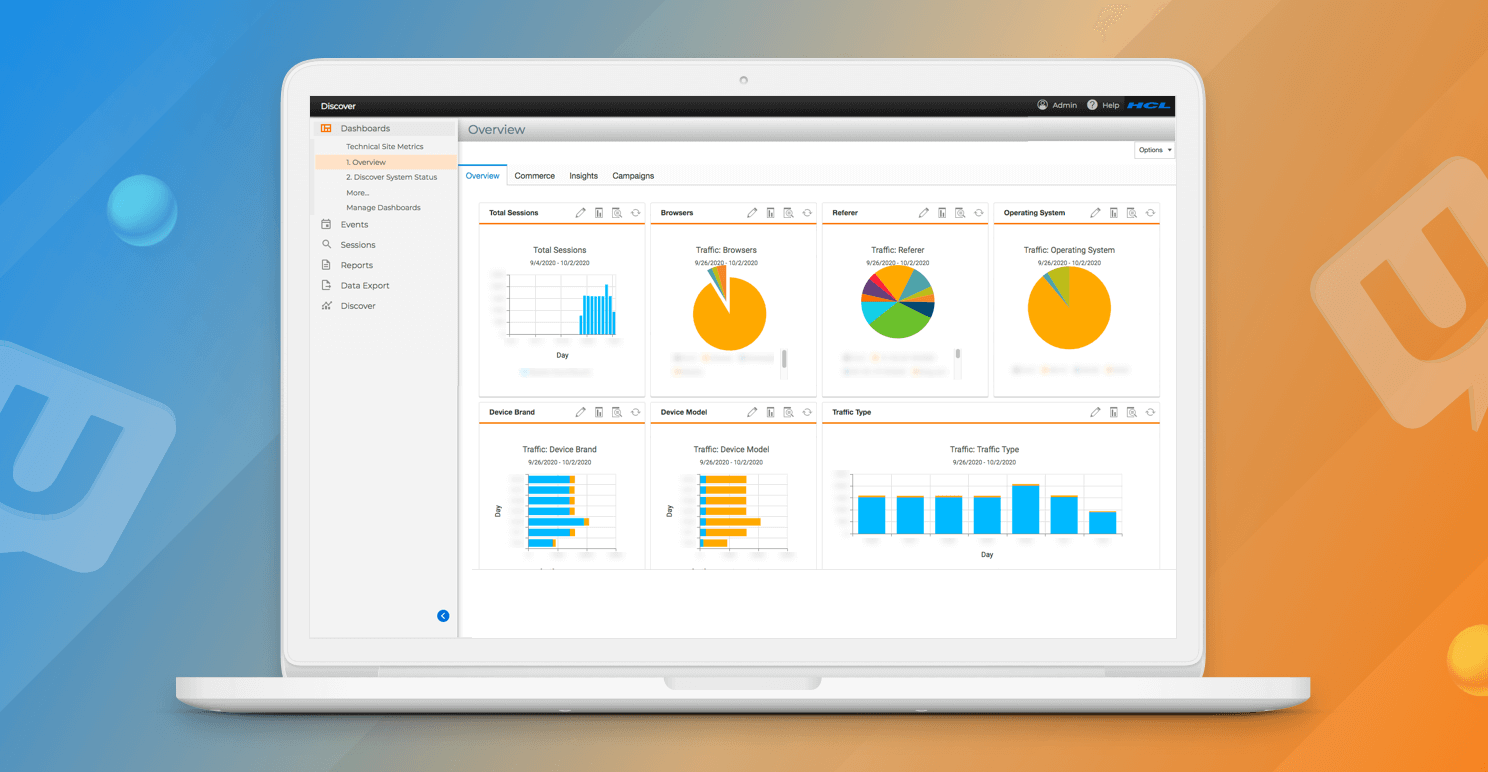
同じデータを通して、行動を分析できるので、ユーザー体験を改善し、ユーザーの苦境やビジネスへの財務的な影響を可視化できます。これらすべての機能により、ユーザーがどのような体験をし、どのような旅をしているのかを可視化し、ユーザーがどのようにサイトを利用しているのかを把握し、どこに痛みを感じているのかを特定する力を得ることができます。そして、それらの体験を解決し、緩和すると同時に、ビジネスへの影響や機会を特定できます。

Unica Discover によって生成されたインサイトは、さまざまな部門でビジネス全体に活用することができ、チャネルを通じて提供する体験を確実にポジティブなものにすることができます。マーケティングは、データを利用してキャンペーン、分析、コマースチームに指示を出し、トラフィックを促進し、コンバージョンを向上させることができます。コールセンターチームは、発信者の問題をより迅速に理解し、製品チームは新たな収益機会を特定することで、解決までの時間を短縮できます。
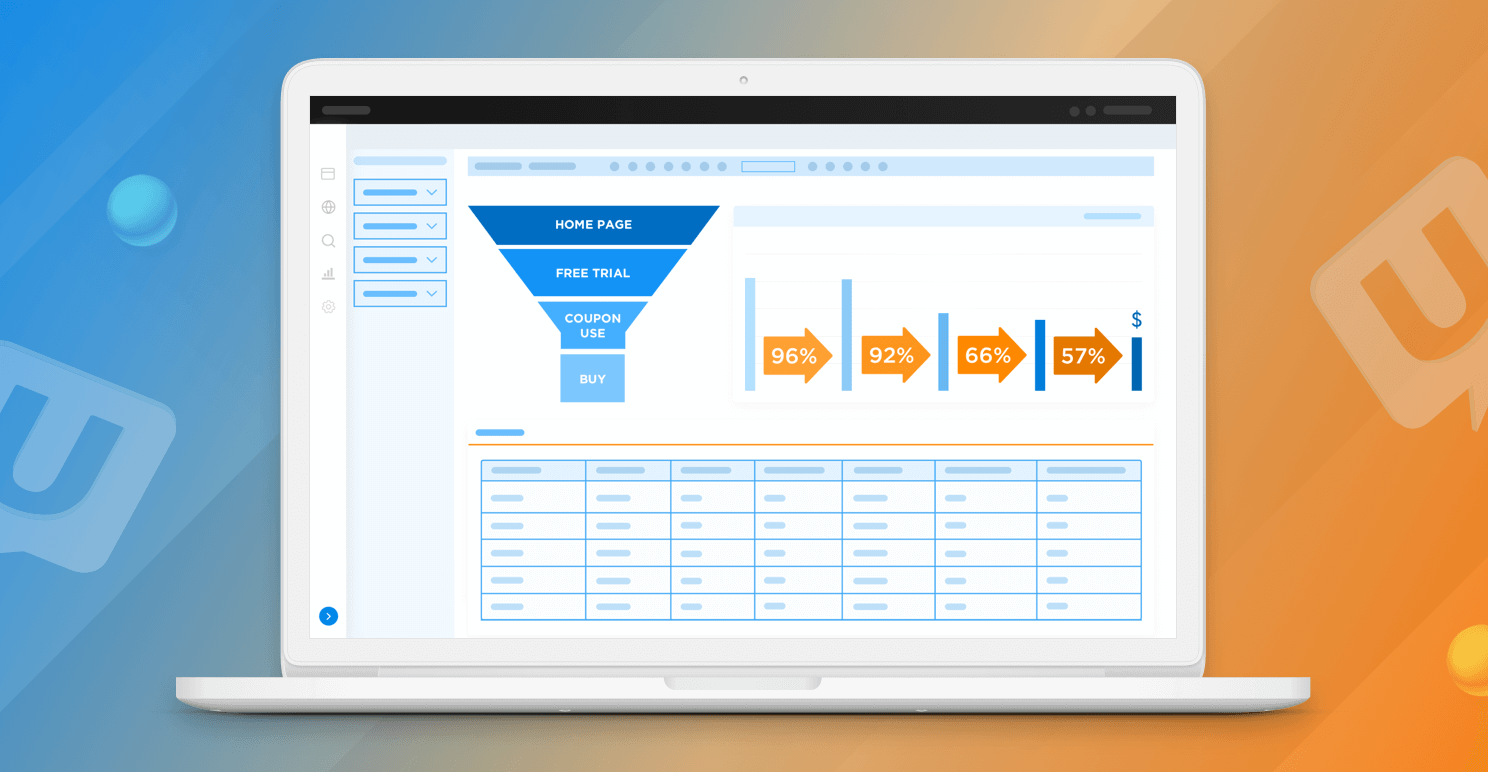
顧客がさらに力を持つようになるにつれ、カスタマー・エクスペリエンスの重要性はますます高まっています。カスタマー・エクスペリエンスは、常に育成とケアが必要な領域であり、カスタマー・エクスペリエンス戦略の策定に重点を置くことで、顧客ロイヤルティの向上、リテンションの向上、解約率の低下、コンバージョンの増加、収益の増加といったプラスの効果を実感できることでしょう。HCL Unica Discover がどのように顧客の価値あるインサイトを収集するのに役立つかについての詳細は、Unica Live のウェビナーをご覧ください。

Unica Discover もご覧ください。
BigFix: COVID-19 のロックダウンが延長される中でのサイバーセキュリティーの問題
2020/10/6 - 読み終える時間: 2 分
Cybersecurity Issues Amid an Extended COVID-19 Lockdown の翻訳版です。
COVID-19 のロックダウンが延長される中でのサイバーセキュリティーの問題
2020年10月5日
著者: Jeremy McNeive / Public Relations Manager

先週、HCL BigFix のジェネラル・マネージャー兼副社長である Kristin Hazlewood は、CyberTheory が主催するサイバーセキュリティー・リーダーシップ・パネルに参加しました。以下は、「サイバーセキュリティ・リーダーシップ」をテーマにした「COVID-19のロックダウンが延長された中での継続的な問題」のトピックについてHazlewood が語ったコメントです。
質問: デバイスやユーザーをプロキシとして利用して企業ネットワーク内のより価値の高い資産に到達する、より複雑なマルウェアの新たな波は、今回のロックダウン中の最大の潜在的な脅威の一部です。この新しい現実の中で、新しい脅威に対応するために新しいテクノロジーに頼ることができるのか、また、それらを十分に迅速に実装することができるのでしょうか。
Hazlewood: エンドポイントの継続的なコンプライアンスの維持を支援するために、インフラストラクチャー内にそれらのセーフティネットを持つことで簡単に対処できる基本的なことを忘れないようにしましょう。自宅で仕事をしているときに、子供がノートパソコンをちょっと貸してくれと言って、その後帰ってきて驚いたことに、自分のシステムに何かが起きてしまったということは、とても簡単なことなのです。
質問: ここ数ヶ月の間、サイバーセキュリティー・コミュニティーは、COVID-19のテーマを囮として、あるいは悪意のある活動を識別や検出から隠す方法として使用する多数の攻撃ベクターを観察してきました。北朝鮮の国営ハッカーは、COVID-19 をテーマにしたフィッシングメールをシンガポール、日本、米国、韓国、インド、英国の 500 万人以上の企業や個人に送信し、個人情報や金融データを盗み出そうとしました。このような新しいメールフィッシングの手法を跳ね返すために、私たちは何をしているのでしょうか?また、それは純粋に人間の問題なのか、それともテクノロジーによる解決策はあるのでしょうか?
Hazlewood: トレーニングとテクノロジーの組み合わせです。今日のリモートワーカーは IT の専門家ばかりではないことを心に留めておかなければなりません。さらに、COVID-19 に対する感情の高まりも加わり、人々はフィッシング攻撃の影響をさらに受けやすくなっています。これらの攻撃に対抗するために、適切なITとセキュリティーのインフラを整備することが、今ではさらに重要になっています。教育は重要ですが、私たちは人間性に注意を払わなければなりません。何度か失敗することもあるでしょう。最終的には、フィッシング攻撃は環境に潜む脆弱性を突くことができて初めて可能になるので、組織が脆弱性を可視化してリスクのある場所を理解し、対策を講じることができるようにするためのツールを持つことが絶対に重要です。
質問: クラウド・コンピューティングへの依存度が高まっている中で、サイバーセキュリティーの観点から最も重要なのはどのような問題でしょうか?エンドユーザーのための過大な依存やプロバイダーと不十分なデリジェンス、第三者による報告のギャップ(SOC2は誰が行っているのか)、MFAや構成管理のような技術的な制限でしょうか?
Hazlewood: ステップ 1 は可視性を持つことです。自分たちのチームがクラウドで何を実行しているのかを知らない組織がたくさんあります。わからないとコントロールも保護もできません。より多くのツールと教育が必要で、より多くの構成とリスクがあることを理解している組織が増えてきています。それは、組織自身とクラウド・プロバイダーが何をもたらすかという責任の共有モデルです。
質問: リモートワークの増加により、2020年には仮想プライベートネットワーク(VPN)とクラウドサービスに攻撃者が集中しますが、昨年のペネトレーションテストのデータによると、クラウドインフラへのアクセスを得るための最良の方法として、多くの侵害がすでにクレデンシャルに焦点を当てていました。パスワードスプレーは、外部からの攻撃者のトップテクニックであることが続いていました。また、WMI と RDP のエクスポージャに対するパッチ適用は依然として課題となっています。リモートワークへの依存度が高まっている世界で、この脅威に対抗するための最も効果的なアプローチは何だと思いますか?
Hazlewood: パスワードがなくなるわけではありませんが、私たちはパスワードから離れたいと思っています。しかし、安全で強制力のあるパスワードポリシー、行動分析の多要素レイヤリング、最小特権の原則を確認することです。これが最初の防御線です。次に、対応について議論し、これらの攻撃が起きているのを見たときに対応する方法があるかどうかを確認してください。どのようにシステムを隔離しますか?どのようにして組織をまとめて対応しますか?
質問: 2021年のサイバーセキュリティーロードマップで最も重要な要素は何でしょうか?
Hazlewood: 「セキュリティーチームと IT チームの連携」です。 多くの場合、セキュリティーチームは知識とツールを持っていますが、IT チームは実装と実施のための人手を持っています。多くの組織では、異なるツールを使用していたり、異なる言語を使用していたり、優先順位が異なっていたりと、このような断絶を目の当たりにし続けています。残念ながら、多くの侵害は、2つのチームが思うように連携していないことが原因となっています。
リーダーシップパネルの詳細はこちらをご覧ください。

HCL BigFix は IBM License Metric Tool (ILMT) として利用可能です
2020/10/5 - 読み終える時間: 2 分
BigFix Inventory V10 Validated Equivalence to IBM License Metric Tool (ILMT) の翻訳版です。
BigFix Inventory V10 は IBM License Metric Tool (ILMT) との同等性の検証を完了
2020年10月5日
著者: Cyril Englert / Solution Architect
HCL BigFix Inventory を使用すると、インフラストラクチャにインストールされているソフトウェア資産の最新のインベントリを維持し、ハードウェアに関する情報を収集し、企業のライセンス・コンプライアンスを確保することができます。BigFix Inventory を使用すれば、どのようなソフトウェアがあり、どこに配備され、どのように使用されているかを常に把握できます。
IBMとHCLは、IBM Virtualization Capacity レポートのための IBM License Metric Tool (ILMT) の代替ソリューションとして BigFix Inventory を継続的に受け入れるための協業契約を締結しました。新しいリリース/アップデートが IBM によって検証された場合、お客様は BigFix Inventory を IBM 仮想化キャパシティーレポート用に使用できるようになります。BigFix Inventory V10.0.0 および V10.0.1 は IBM によって検証されており、BigFix Inventory を使用する組織は IBM Virtualization Capacity ライセンスの要件を満たすことができます。詳細は PDF をご覧ください (英語版、日本語版)
BigFix Inventory のシニア開発マネージャーである Malgorzata Jablonska 氏は、「サブキャパシティのお客様が環境をアップグレードする前に、IBMによるBigFix Inventoryの最新リリースの検証を必要としていることを理解しており、今後もIBMと協力して BigFix Inventory の将来のリリースの検証を行っていきます」と強調しています。
HCL は、以下のような BigFix Inventory の付加的な利点をすべて提供しながら、ILMT に代わる検証済みのインベントリーを提供することに専念しています。
- IBM のソフトウェアだけでなく、Windows、UNIX、Linux、macOS をサポートするソフトウェア・インベントリー・ツール
- ホスト名、DNS名、OS、ネットワークの詳細、CPU の詳細、ディスクの詳細、RAM、ベンダー、シリアル番号を収集するハードウェア・インベントリーツール
- ソフトウェアが使用されているかどうか、どのくらいの頻度で使用されているかを組織が判断するのに役立つソフトウェア測定機能
- ベンダー監査に迅速に対応できるため、組織はソフトウェアライセンスのコンプライアンスを維持し、ソフトウェアの総支出を削減し、コンプライアンス違反の罰金やペナルティーのリスクを排除できます
- ServiceNow© ServiceGraph Connector for BigFix を使用して、エンタープライズ ServiceNow CMDB を最新の状態に保ちます。
BigFix Inventory は多くの組織で効果的な資産管理戦略の重要なコンポーネントです。デモを予約、BigFixスペシャリストにご相談ください。
詳細については、www.BigFix.com をご覧ください。
HCL Accelerate 2.1 のご紹介
2020/10/5 - 読み終える時間: 4 分
Introducing HCL Accelerate 2.1 の翻訳版です。
HCL Accelerate 2.1 のご紹介
2020年10月1日
著者: Bryant Schuck / Product Manager for HCL Software DevOps
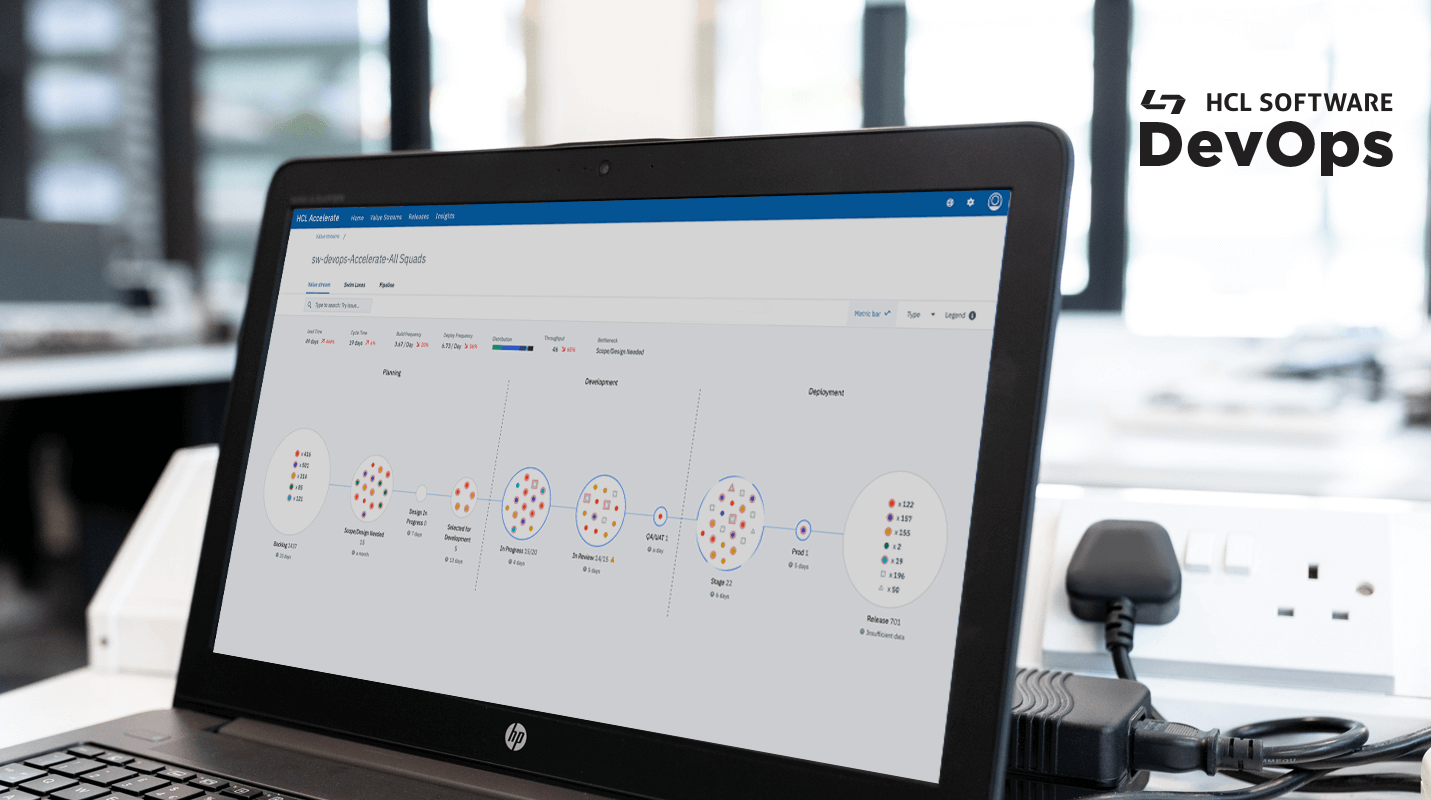
HCL Accelerate は、今、バリュー・ストリーム管理の未来を構築しています。HCL Accelerate 2.1 のリリースでは、この市場における当社の継続的な改善と最先端の機能の提供をご覧いただけます。お客様からのフィードバックと深い市場分析により、当社は、VSMの主要な価値領域に焦点を当て続けることができました。HCL Accelerate をお使いの場合にはアップグレードして、以下の最新機能を試してみてください。まだ HCL Accelerate を使用していない場合は、無料の Community Edition をここでチェックすることで、今すぐ HCL Accelerate を使い始められます。
データ駆動型インテリジェンスによるガバナンスの自動化
-
自動化されたルールベースのゲート - セキュリティと品質データの統合を活用して、自動化されたルールベースのゲートで複数のアプリケーションを単一のパイプラインで管理します。自動プロモート機能を利用して、ハイブリッド集中型フルコントロール CI/CD システムでビルドをより低い環境にシームレスに移行できます。
-
オープンパイプライン - HCL Accelerate の特長は、パイプラインビューです。2.1 では、HCL Launch や Azure DevOps などの市場をリードするデプロイツールと接続する、真にオープンなパイプラインにより、ビルドから本番までの可視性がさらに向上しました。さらに、パイプラインビューのロード時間が 70% 速くなり、常に最新の作業状況を把握できるようになりました。
作業を可視化し、予測可能に
-
新しいバリュー・ストリーム・メトリクス - ロード、スループット、およびディストリビューションの 3 つのメトリクスで、フローがどのように発生しているか、そして顧客に最も価値を提供するために最適な数値は何であるべきかを正確に確認できます。2.1 では、これらのメトリクスはダッシュボードで経時的な傾向を見るためにサポートされているだけでなく、バリュー・ストリームのメトリクス・バーを介して、チーム全体が素早くアクセスできます。
-
強化されたレポート - 新しい「スプリントの状態」レポートでは、Velocity などのメトリクスを活用し、コントリビューターやポイントされたグラフとそうではないグラフなどの重要な情報を組み込むようになりました。また、2.1 の新機能として、ワンクリックでセキュリティ監査を実行し、HCL Accelerate のインスタンスで誰がどのような権限を持っているかを素早く確認できるようになりました。
-
質問に答えられる表示 - バリューストリームを「お気に入り」にして、プロジェクトやチーム間の主要なメトリクスを素早く確認したり、比較したりすることができるようになりました。点や作業項目を確認し、DevOps クエリ言語 'issue.sprints.active=true' の拡張により、スプリントがどのように進行しているかを正確に視覚化します。
バリューを得るまでの時間が早い
-
HCL Software Factory (SoFy) で利用可能 - HCL Accelerate は、HCL Software Factory (SoFy) で利用可能になりました。SoFy は、Kubernetes 対応製品を Docker イメージや舵取り図としてカタログ化したもので、クラウドネイティブのレジストリでホストされています。SoFy がどのようにソリューションを合理化するかについての詳細は、こちらからお問い合わせください。
-
複数のパフォーマンスと安定性の改善 - 私たちは、パフォーマンスと安定性を継続的に改善するよう努めています。今回のリリースサイクルも例外ではありません。技術的な詳細については、こちらの累積リリース情報をご覧ください。
小規模な機能強化
-
リリースオーケストレーションの改善 - リリース機能に様々な改善とバグ修正が行われました。これには、リリース参加者の表示の改善、情報の表示の改善、リリースロックの小さな強化が含まれます。
-
Jenkinsサーバー用の新しいプラグイン(プラグインバージョンv2.1.0) - HCL Accelerate v2.1.0では、Jenkinsサーバー用の新しい改良された v2.1.0 プラグインを使用する必要があります。
-
複数の新しい HCL Accelerate プラグイン
- ブラックダック
- HCLコンパス
- Azure DevOps
- HCL Launch
- まだまだ続く! Docker Hub をチェック
-
既存のプラグインでより多くのデータを
- プラグインのイメージバージョンがUIから明確に表示されるようになりました
- Azure Devops プラグイン。マスター以外の別のブランチをコミットのために追跡できるようにする
- SonarQube プラグイン。正しいビルドにリンクするメトリクスのアップロード
- ServiceNow プラグイン。変更やインシデントと一緒に問題データを引き出す
- Github プラグインのプロキシ対応
- 壊れていたすべてのパーサープラグインの最新バージョンを修正し、すべてのドキュメントを更新しました。
-
新しい Pipeline Designer ロール - この新しいロールは、パイプラインの編集を許可しながらも実行を禁止する権限を持っています。
-
ユーザーリストの改善 - 新しいシングルユーザーリストを使用して、LDAP、SSO、ローカルユーザーを表示できます。
これらの新機能は、10月8日(木)午後2時(EDT)に開催されるウェビナーでご確認ください。参加できない場合でも、サインアップしていただければ、録画を視聴できます。登録するにはここをクリックしてください。

Amazon Redshift データベースで HCL Unica Campaign を設定する
2020/10/5 - 読み終える時間: 10 分
Configuring HCL Unica Campaign with Amazon Redshift Database の翻訳版です。
Amazon Redshift データベースで HCL Unica Campaign を設定する
2020年10月1日
著者: Omkar Pathak / Technical Lead at Unica

最近のマーケターは、これまで以上にデータの活用に関与し、熟練しています。顧客情報は中央データベースから収集、保存、検索され、指数関数的に増加しています。それはマーケターがより具体的でターゲットを絞ったマーケティングコミュニケーションを行い、ユーザーにとってよりパーソナライズされた体験を創造することを容易にします。しかし、データベースの管理や処理は簡単な作業ではなく、クラウドデータベースやDaaS(Database as a Service)プラットフォームが企業に普及してきています。その中で知られているのが Amazon Redshift です。
Amazon Redshift とは?
Amazon Redshift は、大規模なデータセットの保存と分析のために設計されたフルマネージドのペタバイト規模のクラウドベースのデータウェアハウス製品です。クラウド型のデータベースサービスを利用するのが現在のトレンドであり、HCL Unica Campaign ではそのようなサービスとの連携に精通しています。本記事では、Amazon ODBC Driver を利用して、HCL Unica Campaign を Amazon Redshift をユーザーデータベースとして利用するための設定がどのように簡単にできるのかをご紹介します。

前提条件として必要なもの
Amazon Redshift データベースで Unica の設定を開始するには、以下の前提条件が必要です。
Amazon Redshif tデータベースと統合する必要がある HCL Unica Campaign アプリケーション。
- Amazon Redshift の詳細: クラスタ名、データベース名、ユーザーID、パスワード(Amazon Redshif tの契約時にこれらの詳細を取得します。
- Unica UI の Settings -> Configuration のノード「Affinium|Campaign|partitions|partition1|dataSources」で、「(PostgreSQLTemplate)」のデータソーステンプレートが既に追加されていることを確認し、このテンプレートを使用してデータソースを作成できるようにしてください。
- HCL Unicaスイート が Unix ベースの OS にインストールされている場合は、Unica Campaign リスナーがインストールされているサーバに unixODBC 2.3.x をインストールしてください。
サポートされているODBCドライバ
Unica Campaign を Amazon Redshift データベースと統合するには、PostGreSQL ODBC ドライバまたは Amazon ODBC ドライバを使用できます。より良いパフォーマンスとデータベースに関連するすべての機能を利用するには、Amazon ODBC ドライバの使用をお勧めします。理想的には Amazon から入手可能な最新の ODBC ドライバを使用する必要があります。
古い ODBC ドライバは、Amazon 自体がサポートしていません。そのため、サポートされている Amazon ODBC ドライバのバージョンを使用していることを確認する必要があります。現在、Amazon ODBC v1.4.11.1000 が提供されており、Unica Campaign との連携が可能です。これは、Unica Campaign のリスナーが動作しているサーバーにインストールして設定する必要があります。
Amazon ODBC ドライバのインストール方法
Amazon ODBC ドライバをダウンロードしてインストールするには、Amazon が公開している以下のリンクを参照してください。
https://docs.aws.amazon.com/redshift/latest/mgmt/configure-odbc-connection.html
Amazon ODBC ドライバをインストールするために使用できるコマンドの一覧です。
-
RHEL オペレーティングシステム
wget https://s3.amazonaws.com/redshift-downloads/drivers/odbc/1.4.11.1000/AmazonRedshiftODBC-64-bit-1.4.11.1000-1.x86_64.rpm yum --nogpgcheck localinstall AmazonRedshiftODBC-64-bit-1.4.11.1000-1.x86_64.rpm -
Suse Linux オペレーティングシステム
wget https://s3.amazonaws.com/redshift-downloads/drivers/odbc/1.4.11.1000/AmazonRedshiftODBC-64-bit-1.4.11.1000-1.x86_64.rpm zypper install AmazonRedshiftODBC-64-bit-1.4.11.1000-1.x86_64.rpm
デフォルトでは /opt/amazonの 下にインストールされます。
- Windows オペレーティングシステム
以下のリンクから .msi ファイルをダウンロードしてインストールしてください。
odbc.iniファイルの設定
Windows 以外のサーバでは、 odbc.ini という名前のファイルを作成する必要があります。以下は odbc.ini ファイルのサンプルです。
[AMAZONREDSHIFT]
Driver=/opt/amazon/redshiftodbc/lib/64/libamazonredshiftodbc64.so
Host=unica-redshift-cluster.redshift.amazonaws.com
Port=5439
Database=amazondb
Username=awsuser
Password=Password
locale=en-US
BoolsAsChar=0上記の例では、ホスト、ポート、データベース、ユーザー名、パスワードのエントリを Amazon から受け取った通りに変更する必要があることに注意してください。
Windows OS では、以下のリンクを参照して、"ODBC Datasource Administrator (64-bit)" の下にシステム DSN を追加する必要があります。
上記の例では、AMAZONREDSHIFT が DSN 名になっています。
Unica UI で必要な変更
-
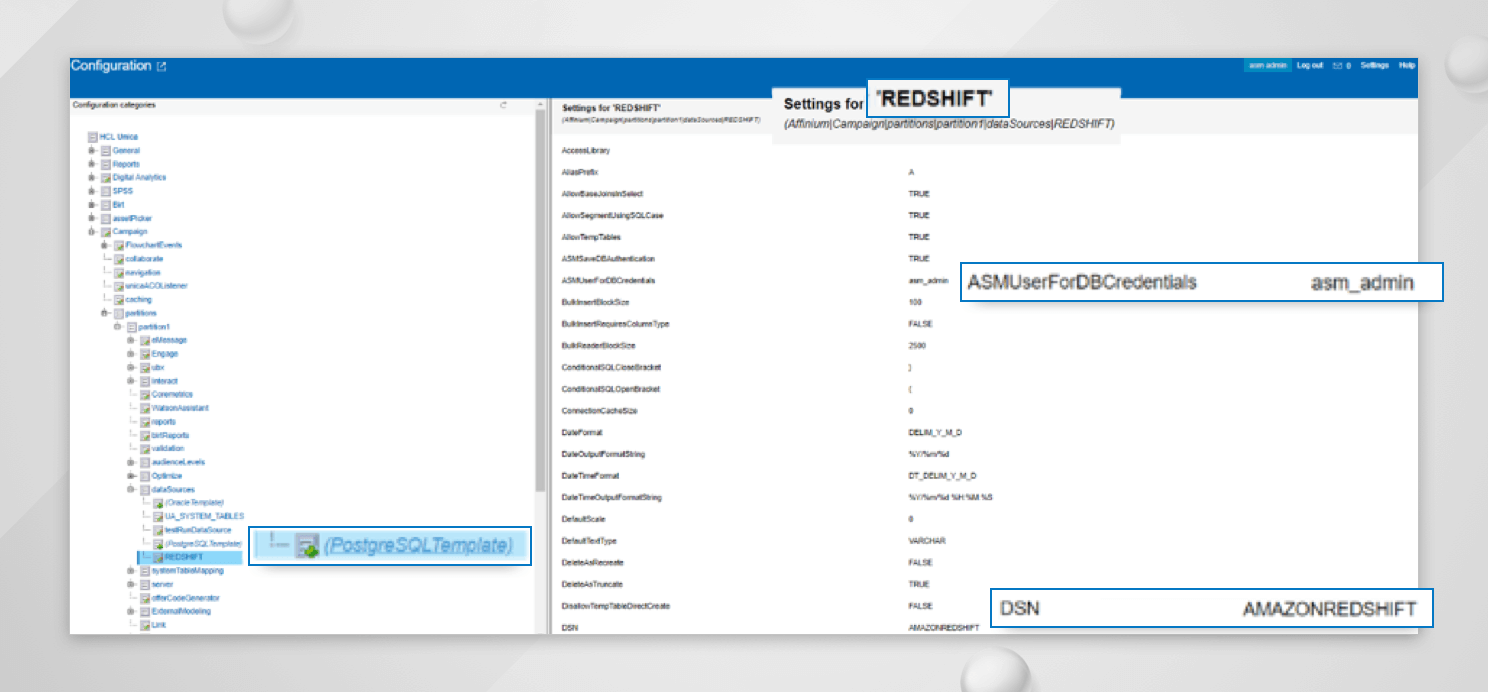
テンプレートを使用して、"Affinium|Campaign|partitions|partition1|dataSources "の下にデータソースを作成します。PostgreSQLTemplate を使用します。
-
- 追加した Datasource については、フィールド DSN の値を、非 Windows OS の場合は odbc.ini ファイルで定義したものと、Windows OS の場合は「ODBC Datasource Administrator (64-bit)」で追加したシステム DSN の名前と同じにしておきます。上記の例のように odbc.ini を設定している場合、DSN の値は AMAZONREDSHIFT に設定する必要があります。
-
User ? asm_adminの下にDatasource 資格情報を追加するか、フィールド ASMUserForDBCredentials の下に定義されたユーザを追加します。
-
- Windows 以外の OS の場合は、<キャンペーンホーム>/binディレクトリで setenv.sh ファイルを編集し、LD_LIBRARY_PATH環境変数に /opt/amazon/redshiftodbc/lib/64 のパスを追加します。また、環境変数 ODBCINI が ODBC.INI ファイルの絶対パスに設定されていることを確認してください。
例
接続性をテストするには
Amazon Redshift データベースへの接続性をテストするには、
cxntest を使う
-
キャンペーンリスナーがインストールされているサーバーのコマンドプロンプトから<キャンペーンホーム>/bin ディレクトリに移動します。
-
setenv.sh/setev.bat を実行します。
-
cxntest ユーティリティを実行します。
-
libodb4dDD.so " を提供します。
-
接続ライブラリ?"プロンプトに "libodb4dDD.so "または "libodb4d.so " をん入力してください。
-
- 設定通りに Datasource Name, UserName, Password を提供します。プロンプト「>」が表示されたら、データベースに正常に接続されていることを示します。
[root@server bin]# ./cxntest
Connection Library? libodb4dDD.so
Registered Data Sources:
Data Sources
AMAZONREDSHIFT
Data Source? AMAZONREDSHIFT
User ID? awsuser
Password? Password
>odbctest の使用
-
キャンペーンリスナーがインストールされているサーバーのコマンドプロンプトから<キャンペーンホーム>/binディレクトリに移動します。
-
setenv.sh/setev.bat を実行します。
-
- odbctest ユーティリティを実行します。
-
- サーバー名、ユーザー名、パスワードを設定通りに入力します。プロンプト「>」が表示されたら、データベースに正常に接続されていることを示しています。
[root@server bin]# ./odbctest
Registered Data Sources:
AMAZONREDSHIFT (/opt/amazon/redshiftodbc/lib/64/libamazonredshiftodbc64.so)
Server Name? AMAZONREDSHIFT
User ID? awsuser
Password? Password
Detected Data Direct compatibility
Server AMAZONREDSHIFT conforms to LEVEL 2.
Server's cursor commit behavior: PRESERVE
Transactions supported: ALL
Maximum number of concurrent statements: 1
For a list of tables, use PRINT.
>また、Windows 以外のサーバで "isql -v AMAZONREDSHIFT " コマンドを使用して接続をテストできます。"ODBC Datasource Administrator (64ビット) on Windows OS " から直接接続をテストします。
Amazon Redshift Loader を設定するには (オプションステップ)
デフォルトでは、Unicaは大量のデータをロードするためにBULK INSERTを利用しています。BULK INSERTよりも優れたパフォーマンスを利用したい場合は、"COPY "コマンドの実装を使用してamazon redshiftローダを利用できます。Amazon Redshiftデータベース側でのローダーの動作を理解するには、チュートリアルを参照してください。
AWS側でのローダーに関する設定
AWSサポートに連絡して、以下の手順を行う必要があります。
-
AWS 側に S3 バケットを作成します。
-
AWS_ACCESS_KEY_ID と AWS_SECRET_ACCESS_KEY を集めてAWS データベースに接続します。
-
Unica Campaign Listener がインストールされているサーバーに AWS Cli ユーティリティをインストールします。
-
aws configure コマンドでS3バケットに接続するために必要な設定を行う必要があります。
上記の手順が完了したら、コマンドプロンプトから直接以下のテストを行う必要があります。
データファイルをS3バケットにコピーする場合 (ここでは、
copy <TABLE> from 's3://s3bucketaws/<DATAFILE Name>' credentials 'aws_access_key_id=<Your-Access-Key-ID>;aws_secret_access_key=<Your-Secret-Access-Key>' csv;
テーブルへのデータの読み込みは、任意のツールからデータベースに接続し、以下のコマンドを実行します。
DATAFILE=$1
TABLE_NM=$2
export S3BUCKET=[Change me]
export AWS_ACCESS_KEY_ID=[Change me]
export AWS_SECRET_ACCESS_KEY=[Change me]
export DSNNAME="AMAZONREDSHIFT" #Change this value as per your odbc.ini
ERR_CD=1
LOG_FILE="/tmp/log.$$"
FILE_NM=`basename $1`
S3_FILE=$S3BUCKET$FILE_NM
echo "file to copy is $1"
echo aws s3 cp $1 $S3BUCKET >> $LOG_FILE 2>&1
aws s3 cp $1 $S3BUCKET >> $LOG_FILE 2>&1
RESULT=$?
if [ ${RESULT} -ne 0 ]; then
echo "ERROR in aws s3 cp" >> $LOG_FILE
exit $ERR_CD
fi
COMMAND="COPY $TABLE_NM FROM '$S3_FILE' CREDENTIALS 'aws_access_key_id=$AWS_ACCESS_KEY_ID;aws_secret_access_key=$AWS_SECRET_ACCESS_KEY' csv"
echo $COMMAND > /tmp/sql.$$
isql $DSNNAME < /tmp/sql.$$
RESULT=$?
echo "RESULT is $RESULT"
if [ ${RESULT} -ne 0 ]; then
echo "ERROR in COPY" >> $LOG_FILE
exit $ERR_CD
fi
# remove file from s3?
aws s3 rm $S3_FILE
echo "LOG_FILE is $LOG_FILE"
exit 0上記のコマンドをコマンドプロンプトから直接 (Unicaからではなく) テストに成功したら、Unica 側で必要な設定を行っていきます。万が一、上記の手順のテストで問題が発生した場合は、AWS のサポートに連絡して、上記のテストが成功しているかどうかを確認してください。
さて、2つの引数を受け入れるシェルスクリプトを作成する必要があります。DATAFILE PATH と TABLENAME です。このスクリプトが正常に実行され、コマンドプロンプトから直接実行されたときにテーブルにデータをロードできることを確認してください。以下にサンプルローダースクリプトの例を示します。
HCL Unica側での構成
ローダースクリプトを
loaderCommand = /opt/Unica/campaign/partitions/partition1/scripts/amazonload.sh <DATAFILE> <TABLENAME>
loaderCommandForAppend = /opt/Unica/campaign/partitions/partition1/scripts/amazonload.sh <DATAFILE> <TABLENAME>
loaderDelimiter = ,
loaderDelimiterForAppend = ,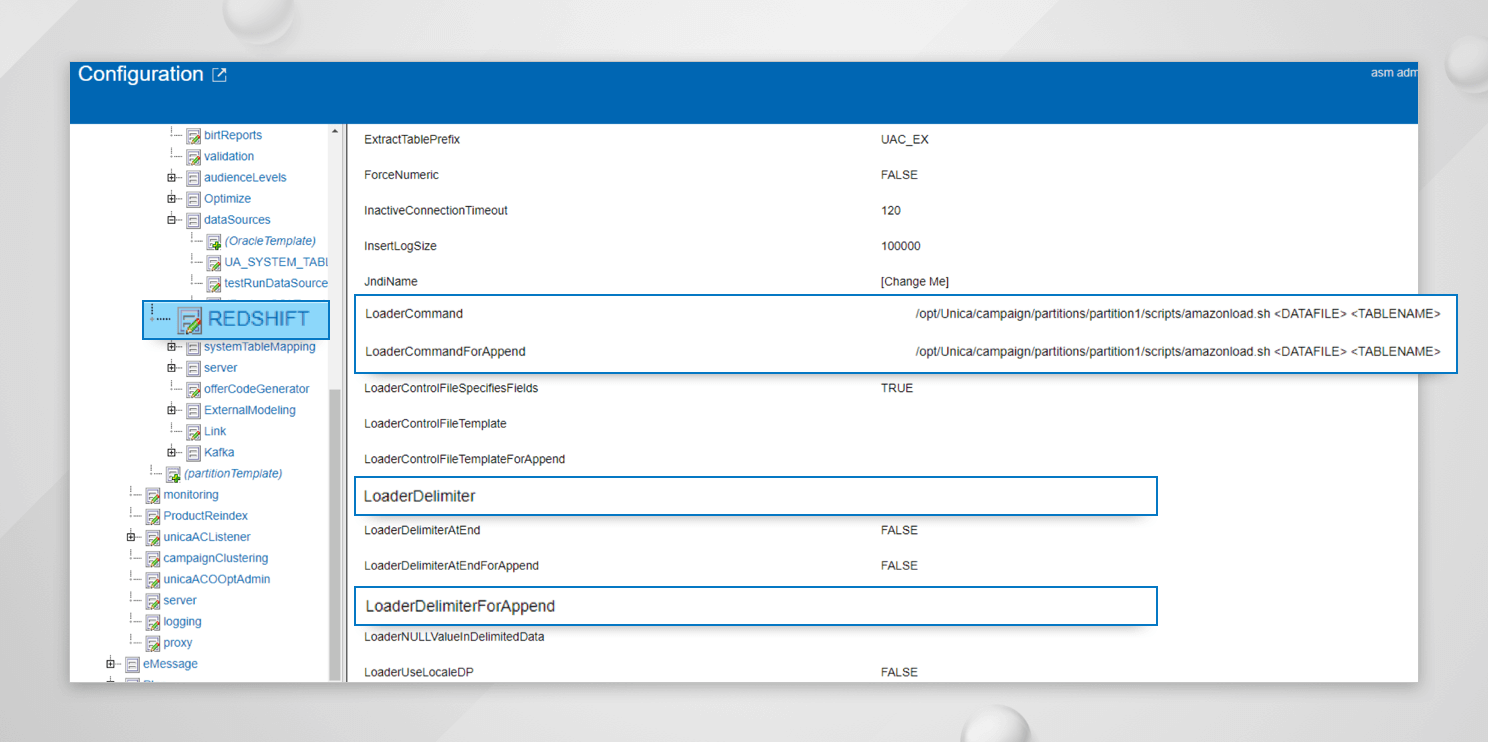
ODBC トレースを有効にするには
何らかの問題をトラブルシューティングしたい場合、ODBC トレースレベルのロギングを有効にする必要がある場合があります。トレースレベルのロギングを有効にするには、以下のように /opt/amazon/redshiftodbc/lib/64 の下にある "amazon.redshiftodbc.ini "というファイルを更新する必要があります。
[root@server 64]# cat amazon.redshiftodbc.ini
[Driver]
## - DriverManagerEncoding is detected automatically.
## Add DriverManagerEncoding entry if there is a need to specify.
ErrorMessagesPath=/opt/Campaign/redshift_odbc_logs
LogLevel=6
LogPath=/opt/Campaign/redshift_odbc_logs
SwapFilePath=/tmpLogLevel=6 は、トレースレベルのロギングが有効であることを示しています。LogPath と ErrorMessagesPath には、任意のフォルダの場所を指定できます。トレース・レベル・ロギングを無効にするには、LogLevel を 0 に更新する必要があります。 トレース・レベル・ロギングを有効にするには、"ODBC Datasource Administrator (64-bit) on Windows OS "から行うことができます。
いくつかの既知の問題があります。
-
Amazon ODBC Driver v1.4.3.1000 は Amazon Redshiftデータベースでの BULK INSERT をサポートしていません。これは、このバージョンのドライバの制限です。
-
Amazon ODBC Driver v1.4.4.11.1000 では、Snapshot や Extract などのアウトバウンドプロセスボックスで Flowchartname や Cellcode などのキャンペーン生成フィールドをエクスポートしている場合、そのようなフィールドのデータ型は BOOL とみなされ、フローチャートの実行に失敗します。この問題を解決するには、 odbc.ini ファイルに "BoolsAsChar=0" を追加する必要があります。
-
PostGreSQL v9.6.5 を使用して Amazon Redshift データベースに接続している場合、プロセスボックスに表示されている挿入/更新されたレコードの数が、実際に影響を受けた数と一致しないことがあります。これは PostGreSQL v9.6.5 の既知の問題です。誤ったカウント表示の問題を回避するために、Unica で v9.03.0100 の使用をお勧めします。
-
PostGreSQL ドライバ(すべてのバージョン)は、Amazon Redshift データベースでの BULK INSERT をサポートしていません。これはこのドライバの制限です。
Amazon Redshift では、スケーリングが容易で、何千もの同時クエリが実行されている場合でも、Unica Campaign との相性が良く、一貫して高速なパフォーマンスを提供します。Amazon Redshift と Unica Campaign の統合についての詳細は、弊社までお問い合わせください。
Search
Categories
- Aftermarket Cloud (2)
- AppScan (178)
- BigFix (198)
- Cloud (14)
- Cloud サービス (1)
- Collaboration (625)
- Commerce (23)
- Customer Data Platform (1)
- Data Management (3)
- DevOps (223)
- Domino (1)
- General (237)
- News (11)
- Others (4)
- SX (1)
- Total Experience (13)
- Unica (171)
- Volt MX (75)
- Workload Automation (18)
- Z (48)