2020 HCL Domino Volt Hackathon 開催のおしらせ
2020/10/2 - 読み終える時間: ~1 分
2020年10月16日 更新: 期間を延長しました。
HCL Software Digital Solutions Digital Week 2020 のイベントを今秋にオンライン開催を予定していますが、それにあわせて、2020 HCL Domino Volt Hackathon を開催します。応募期間は 2020年10月1日から11月26日です (連絡が遅くなり申し訳ありません)。
豪華優勝副賞も用意しております。みなさまから応募をお待ちしております。詳細は以下のページをご覧ください。
HCL Accelerate 2.1 の新機能: 自動化されたルールベースのゲートを使用したパイプラインガバナンス
2020/10/1 - 読み終える時間: ~1 分
Pipeline Governance with Automated Rule Based Gates, new in HCL Accelerate 2.1 の翻訳版です。
HCL Accelerate 2.1 の新機能: 自動化されたルールベースのゲートを使用したパイプラインガバナンス
2020年9月30日
著者: Bryant Schuck / Product Manager for HCL Software DevOps

バリューストリーム管理と聞くと、メトリクス、主要業績評価指標(KPI)、可視性を思い浮かべるかもしれませんが、HCL Accelerate は2.1 のリリースでそれをさらに向上させています。
2.0 では、ユーザーが手動でバージョンを承認または拒否することができる単一の場所を提供していましたが、エクスペリエンスを向上させることができることがわかっていました。そこで私たちは、DevOps データレイクとデータの深い複雑な関係を活用して、セキュリティルールと品質ルールを導入することで、ゲートを迅速に強化しました。
多くの開発チームにとってパイプラインは、CI/CD ツールがバラバラでプロセスが複雑なワイルドウェストであり、情報が失われる可能性のある領域を生み出しています。例えば、計画されていなかった Pull Request が、実際にはリリースの最終ビルドに含まれていたという状況があるかもしれません。その場合、この小さな変更が壊滅的な脆弱性をもたらしていた可能性があります。作業項目がなかったため、誰も変更が入るとは予想していなかったので、手遅れになる前に誰も戻ってセキュリティ脆弱性の結果をチェックしなかったのです。
これらは、私たちのほとんどが夜も眠れない原因となっています。さらに悪いのは、ツールでレポートをチェックしたり、他の部署に連絡したり、回答を待ったりするためにリリースを遅らせなければならない場合です。より速く、より良い品質を実現する唯一の方法は、プロセスを自動化することです。自動化されたルールベースのゲーティングでできることに飛び込んでみましょう。
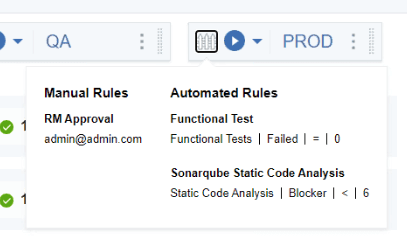
まず最初に気づくのは、新しいルールが2.0の手動ルールをベースにしていることです。多くのお客様がBETAモードでこれを使用してきました。彼らは、すべてのツールを HCL Accelerate に接続していませんでしたが、手動ルールを使用して、どのツールが必要で、いつ接続できるかという目標を設定することから始めていました。アプリケーション・セキュリティ・スキャン・ツールを探しているのであれば、AppScan を強くお勧めします。
自動化されたルールは、コードカバレッジ、機能テスト、ユニットテスト、アプリケーションの脆弱性、コンテナの脆弱性、静的コード解析など、HCL Accelerate でおなじみのあらゆる種類のメトリクスをチェックすることができます。最も良い点は、これらが設定されると、バージョンに関連付けられたデータを完全に自動分析して実行するため、基準を満たさない限り、どのバージョンもこれらのゲートを通過しないことを信頼できるということです。しかし、心配しないでください - 私たちはすべてのコードを出荷しなければならなかったので、常に「確かですか?」という回避策がありますが、それは監査報告書にキャプチャされます。この機能は、実際には、チームが完全な自律性を持って顧客にできるだけ早くリリースできるようにするためのチェックとバランスを整えることです。 「自分はブロッカーが 0 であると言ったけど、あの時、自分は本当に正しいビルドを見ていたのか」などということを、徹夜して言い出すことがなくなります。
いつものように、質問があれば私や私のチームの誰にでも連絡してください。デモをお見せして、HCL Accelerate とバリュー・ストリーム・マネジメントがどのようにしてチームがタスクに集中することをやめ、より多くの価値を提供できるかをお見せしたいと思っています。
Launch: スナップショットに恋して
2020/9/30 - 読み終える時間: 2 分
HCL Launch – In Love with Snapshots の翻訳版です。
HCL Launch - スナップショットに恋して
2020年9月29日
著者: HCL Software
アプリケーションをサーバにデプロイする際の最大の課題のひとつつは、すべてのシステム要件が必要な構成で設定されていることを確実にすることです。アプリケーションが配置されなければならないすべてのサーバの手動チェックと設定は、面倒で、面倒で、エラーが発生しやすいものです。これが単一の変更のデプロイの場合は、3000以上の変更と数千台以上のサーバへのデプロイの場合を考えてみてください。このような懸念に対処するために、HCL Launchの スナップショット機能を効果的に使用できます。
スナップショットとは何ですか?
HCL Launch では、スナップショットは、単一のデプロイ可能なユニットを表すコンポーネント/バージョンの関連付けのバンドルです。
スナップショットは、アプリケーションが正常にデプロイされた環境で作成されたすべての構成のコピーを作成し、この構成の詳細を使用して、最も成功する可能性の高いいくつかの本番環境/サーバーにアプリケーションをデプロイするために使用できます。
言い換えれば、スナップショットはデプロイを実行する必要があるサーバー/環境のすべての設定を処理します。
スナップショットには、ユーザーがスナップショットの構成をロックできる機能もあり、デプロイを成功させるためにすべてのリソースの構成を保持しながら、ユーザーがスナップショットの外で関連する構成を変更できる柔軟性を提供できます。スナップショットの構成がロックされると、それを元に戻すことはできません。このように、スナップショットを活用して、デプロイメントのあらゆる複雑な詳細を設定できます。
クオリティゲートを使用したスナップショット
HCL Launch では、品質ゲートを環境に設定して、特定の基準を満たすコンポーネントバージョンのアーティファクトのみのデプロイを確実にすることができます。
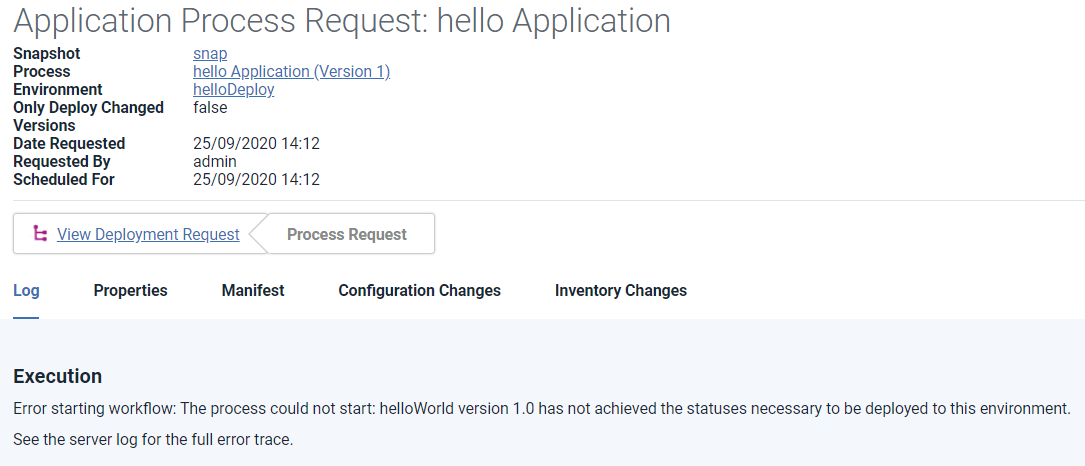
アプリケーションのデプロイがスナップショットを使用して実行されると、各スナップショット内の単一のコンポーネントバージョンが品質ゲート要件に準拠していない場合でも、デプロイは「ワークフローを開始するエラー」というエラーで中止されます。プロセスを開始できませんでした。<コンポーネント名> <バージョン番号>は、この環境にデプロイするのに必要なステータスを達成していません。完全なエラートレースについては、サーバーログを参照してください。
スナップショットと品質ゲートの関係を理解することが不可欠なのはなぜですか?スナップショットが特定のリリースの構成のゴールドコピーであっても、スナップショットのコンポーネントバージョンの1つに深刻な問題がある場合があり、このバージョンは、品質ゲートによってブロックされている特定のステータスを割り当てることでデプロイからゲートされ、スナップショットが各バージョンをデプロイできないようになっている場合があります。スナップショットと品質ゲートを組み合わせることで、本番環境で品質の高いデプロイを成功させることができます。
アプリケーションプロセスのスナップショットと現在のバージョン
アプリケーション・プロセスのバージョン・プリセットは、アプリケーションプロセスがデフォルトで使用するコンポーネントバージョンを設定できる機能です。
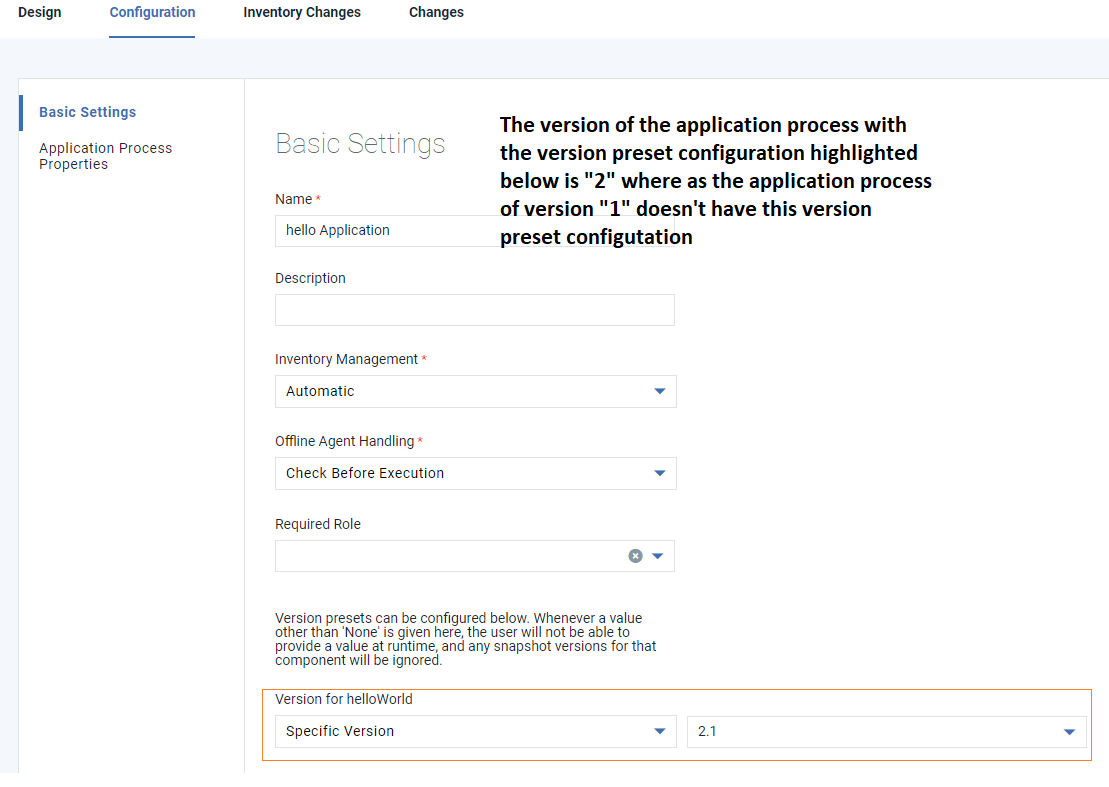
ユーザーがアプリケーションプロセスのバージョンプリセット設定をバイパスするオプションや回避策を探している場合は、スナップショットを使用して実現できます。
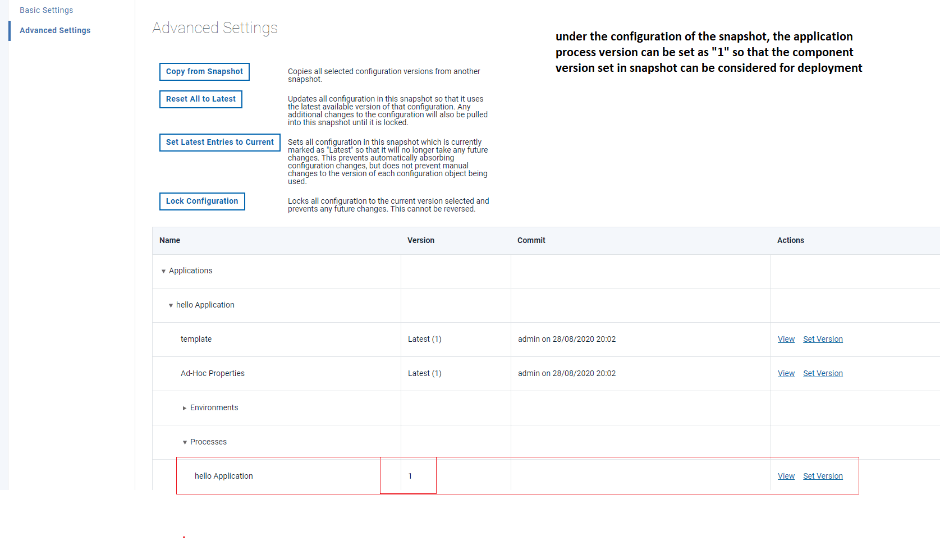
スナップショット設定の[事前設定]タブで、ユーザーは、バージョンプリセット設定の詳細を持たない各アプリケーションプロセスの特定のバージョンを選択でき、デプロイメントをプリセットバージョンではなく、スナップショットで設定されたコンポーネントバージョンで実行できます。
ロールバックが簡単に
本番環境でデプロイに障害が発生し、本番環境を確実にバックアップするためには、すべての障害を分析する必要があります。デプロイメントを以前のバージョンにロールバックして、設定からデプロイまでのすべてのステップを踏んで、デプロイメントプロセスを最初のステップからやり直す必要があります。これにはかなりの時間がかかります。
スナップショットを使用すると、このプロセスがはるかに簡単になります。デプロイに失敗した後、以前にデプロイされたスナップショットを使用して、デプロイ可能なコンポーネントを再デプロイできます。
スナップショットは、HCL Launch の非常にリソースの多い機能であり、管理が容易な高速で堅牢なデプロイメントを保証します。特に手動でのデプロイのセットアップが苦手な人は、スナップショットを気に入ることでしょう。
Accelerrate: データ駆動型 DevOps パート 2: データ駆動型の文化
2020/9/30 - 読み終える時間: 2 分
data-driven-DevOps%e2%80%afpart-2-data-driven-culture の翻訳版です。
データ駆動型 DevOps パート 2: データ駆動型の文化
2020年9月29日
著者: Steve Boone / HCL Software DevOps Head of Product Management
シリーズのパート1を読むにはここをクリックしてください。
堅固な文化は、どのような DevOps 組織にとっても非常に重要です。DevOps 文化の主要な特徴は、開発チームと運用チーム間のコラボレーションを強化し、サポートするアプリケーションの健全性と健全性に対する責任感を共有することです。これは、開発、IT/オペレーション、および「ビジネス」を横断する透明性、コミュニケーション、およびコラボレーションを高めることを意味します。職場内の文化的規範は、優先順位、コラボレーションの方法、問題解決のアプローチに関して意見の相違につながることがよくあります。特に最終的な目標や価値が誰にとっても明らかでない場合は、DevOps 文化は新しい働き方を採用するのに苦労することがあります。
このような文化の移行を容易にするにはどうすればよいのでしょうか?それはデータです。データは、チーム間の知識の公平性を提供することで最大の効果を発揮します。理想的には、優れたデータがあればあるほど、より良い知識を得ることができます。この新しい知識があれば、より効果的に仕事をし、より明確にコミュニケーションを取り、最終的には組織としての働き方を改善するために行動を起こすことができるようになります。つまり、データは、人々が互いに協力し、協力し合う方法を劇的に改善することができるのです。
カルチャーを改善したい場合、どのようなデータを調べればよいのでしょうか?手をつけるべき場所には事欠かないが、HCL Software DevOps での経験から、私たちは開発者、デザイナー、アーキテクトなど、個々の貢献者にとって最も馴染みのあるデータから始める傾向がある。これは通常、ソース・コントロール管理や、課題追跡やプロジェクト管理に関連するデータ(ソースの例としては、Atlassian、JIRA、Gitなどがあります)から来るデータです。
これらのツールから得られるデータからは、多くの分野の洞察が得られます。まず、コードをコミットし、コードの変更をビジネス価値のある特定の項目に関連付ける際に、チームメンバーが使用し、最もよく知っているプロセスを示します。これにより、日々の活動をよりよく理解し、改善点を見つけることができます。また、このデータを使用して、作業中のアプリケーションを特定したり、多くの場合、作業のタイプ(例えば、欠陥と機能)を特定することもできます。このデータは、特定のチーム全体の仕事の分布についての有用な洞察を引き出すために使用することができ、 チームがどのように連携して仕事をしているかを示すことができます。
個々の貢献者から得られるデータを調べることで、以下の7つの主要な分野で文化を改善することができます。
-
誰が何に取り組んでいるか? 誰が何に取り組んでいるか? 誰がどのような作業をしているかを知ることは、優先順位に変更があった場合や要件が変更された場合に備えて、開発マネージャやチームの残りの部分を常に把握しておくのに役立ちます。
-
何か重要なものが取り残されていないか? 進行中の作業を特定することができれば、そのリストをビジネスゴールや成果物のリストとクロスリファレンスすることができます。これにより、「やるべきことに取り組んでいるか」という質問に、より明確に答えられるようになり、時間通りに終わらないかもしれない項目を特定したり、優先順位をつけずに行われている作業を見つけることができます。
-
誰が助けを必要としているのか? 遠隔地で働くスタッフが増えた今、手を挙げて助けを求めるのは難しい。多くの場合、最も優秀な従業員は、彼らの皿の上にあまりにも多くの仕事を抱えてしまうことになります。データを見ることで、仕事を完遂するのに苦労している貢献者を特定し、必要な助けを得ることができます。また、このデータは、時折行われる消防訓練で少し余力のある人を見つけるのにも役立ちます。
-
チームが日々の活動をどのように行うかを改善する。 どのプロセスにも改善の余地があります。より明確なデータがあれば、開発チームが使用しているシステムとどのように相互作用しているかを評価することができ、コードレビューからテストツール、バックログの項目のトリアージまで、ビジネス価値をより効率的に流すことができないボトルネックを明確にすることができます。
-
チームの速度を特定することで、計画を改善する。 進行中の作業を特定することで、どのような作業が完了したかを把握することができます。これにより、チームのベロシティを把握することができ、特定のスプリントやリリースに何をコミットできるかを容易に把握することができます。
-
スプリント/リリースのスコープがより良くなります。 リリースやスプリントに何をコミットできるかを知ることで、チーム全体がより個人的に責任を持ち、達成された仕事に「納得」するようになります。チームは、短い時間枠の中で過剰な成果を求められていると感じることが少なくなります。
-
予定外の仕事を識別する。 計画外の作業は、時間通りに納品されないビジネス価値の最大のサイレントキラーです。チームがどのような開発努力をしているかを分析することで、そのデータを見て、計画的な作業と計画外の作業のどちらが多いかを判断し、計画外の作業の影響を最小限に抑えるための是正措置を取ることができます。
これらの分野に共通しているのは、開発チーム全体のコラボレーションとコミュニケーションの改善に焦点を当てていることです。個々の貢献者が自分に何が期待されているのかを知り、目標が明確に定義されている場合、貢献者はより積極的に参加し、日々の活動に価値を見出し、成功する可能性が高くなることがわかります。
データは非常に個人レベルでも支援する能力を持っています。DevOps Institute の 2020 Upskilling: Enterprise DevOps Skills Report の調査結果によると、DevOps 人材の採用を検討している企業では、新規採用の要件として「ヒューマンスキル」が上位にランクインしています。上位に挙げられたヒューマンスキルの1位は何だったのでしょうか?コラボレーションと協調性、次いで共有と知識の伝達、そして適応性、共感性。これらのヒューマンスキルはすべて、DevOps 文化がデータを受け入れることで成長させることができます。
DevOps Institute のレポートから得られた重要な調査結果の1つは、雇用主が「E字型」のスキルセットを持つ潜在的な候補者を見つけたいと考えていることでした。I字型、T字型、E字型のスキルセットについてよく知らない方は、下の図をご覧ください。I型スキルセットはスペシャリストです。彼らの知識は、一つのテーマについて非常に深いものです。T型のプロファイルは、特定の領域の専門家でありながら、ビジネス全体に関する幅広い一般的な知識を持っています。このため、機能横断的なチームとの連携を得意とし、より広い戦略をまとめる上で優位に立つことができます。E型スキルセットは、さらに一歩進んだものです。このような人材は、プロセスやフレームワークのスキルの専門知識だけでなく、幅広いヒューマンスキルを持っており、自動化の経験、新しいアイデアを探求する能力、高いレベルで実行する能力を備えています。
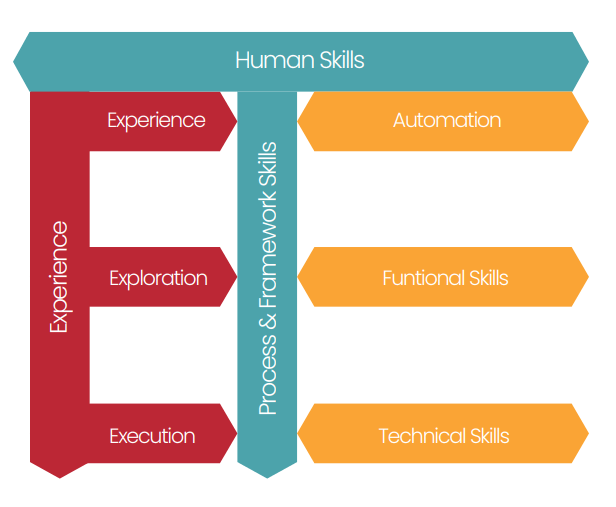
出典: DevOps インスティテュート
データは、個人が通常の役割以外の仕事に触れることで、「T字型」のスキルセットがより「E字型」の未来へと成長するのを支援する上で重要な役割を果たすことができる。このような経験は、共感を生み出し、積極的な DevOps 文化に不可欠な責任感を共有する感覚を高めるのに役立ちます。自分のコントロール外に存在する課題を他者が理解できるようにすることで、組織が真の意味で DevOps を受け入れるために必要な健全な対話を始めることができます。
データは DevOps に変革的なメリットをもたらす可能性があります。次回は、データがどのようにして組織がより効果的に作業を追跡し、計画を立てるのに役立つかについて説明します。最後までお読みいただきありがとうございました。
Accelerrate: データ駆動型 DevOps パート 1: 序章
2020/9/29 - 読み終える時間: ~1 分
Data-Driven DevOps Part 1: An Introduction の翻訳版です。
データ駆動型 DevOps パート 1: 序章
2020年9月28日
著者: Steve Boone / HCL Software DevOps Head of Product Management
ソフトウェア開発の専門家が DevOps について議論するとき、多くの場合、人、プロセス、テクノロジーを中心とした3つの主要な会話が形成されます。これら3つのコンセプトは、DevOps の核心を語るものです。
人」のトピックは、コラボレーションと責任の共有をサポートする健全な文化を構築することに焦点を当てています。プロセスについて議論する場合、会話は特定のワークフローをいかに効率的にできるかに傾く傾向があります。DevOpsのテクノロジーの側面は、ソフトウェア開発における近代化、セキュリティの脆弱性、品質保証、自動化、その他多くの要因に至るまで、常に変化し続ける会話です。私たちは、何がうまくいき、何がうまくいかないかを判断するために、このような会話をしています。私たちは、これらの会話を DevOps が生み出す貴重なフィードバックサイクルの一部として受け入れ、日々の責任を改善する方法を学べます。
すでに DevOps の旅を始めている組織にとって、このような会話は日常生活の一部となっています。振り返りから計画会議まで、1週間を通していくつかの会議が行われますが、これらはすべて、組織全体がこれまでの行動から学び、より良い計画立案の支援に焦点を当てています。これらの会議は、組織のさまざまな部分がそれぞれの意図を共有し、より効果的に協力し、高品質のソフトウェアをリリースするために必要なすべての可動部分をよりよく理解するための素晴らしい方法です。この種の会議の欠点は、主に個人的な経験に基づいていることです。会話に参加している人は皆、自分の視点、自分の主張を示すためのデータ、そして(おそらく最も重要なのは)自分の感情を持ってきます。このため、全員の意見を一致させ、同じ目標に向かう努力は非常に困難です。それはまた構成のある部分にグループの残りの部分より競争の優先順位があれば職場内の分裂を作成できます。
バリューストリームマネジメント (VSM) は、このような継続的な議論から生じる多くの課題を解決できる DevOps のプラクティスとして位置づけられています。VSM の基本的な概念の中で、組織は、機能を市場に投入するために必要なアイデアから納品までのすべてのステップをよりよく理解できます。VSM は、組織のプロセスをマッピングするというコンセプトに基づいています。これには、貢献しているすべての主要なビジネスユニット(設計、開発、製品管理、リリースエンジニア、品質保証、セキュリティなど)と協力して、現在のビジネスがどのように運営されているかを正直に表現し、改善すべき領域を見つけることを目的としています。マッピングはプロセス全体を全体的に見るための素晴らしい方法ですが、ひとつの重要な要素が欠けています。
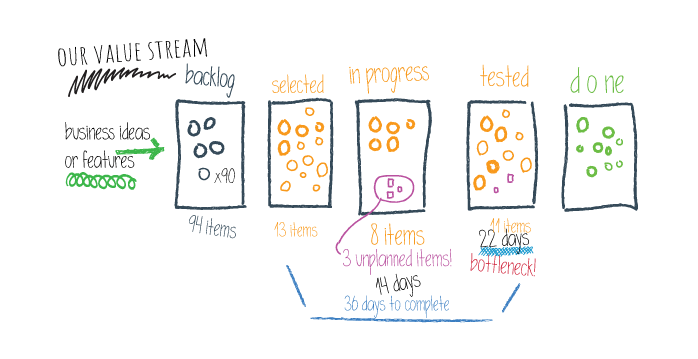
バリューストリームから生み出されるデータを収集・分析することで、あらゆるチームが直面する古くからの疑問の謎を解き明かす鍵を握っています。どこを改善できるのか?何がうまくいっているのか?何がうまくいっていないのか?データ自体は懐中電灯のような役割を果たし、組織が実際にどのように日々運営されているのか、有用な洞察を照らし出せます。これは、我々はプロアクティブに反応していることから会話をシフトすることができることを意味します。 反応的な会話は、ほとんどの場合、問題を理解し、何が問題を引き起こしたのかを理解し、最終的に問題の解決策を議論することに費やされます。プロアクティブな会話は、グループがリアルタイムで何が起こっているかを見ることができるときに行われます。リアルタイムのデータは、問題を予測し、痛みが現実になる前に解決策を実行に移すことを可能にします。データに基づいた会話をすることで、問題がどこにあるのか、より重要なのはなぜ問題なのかを関係者全員が明確にできるため、問題解決をより迅速に行うことができます。
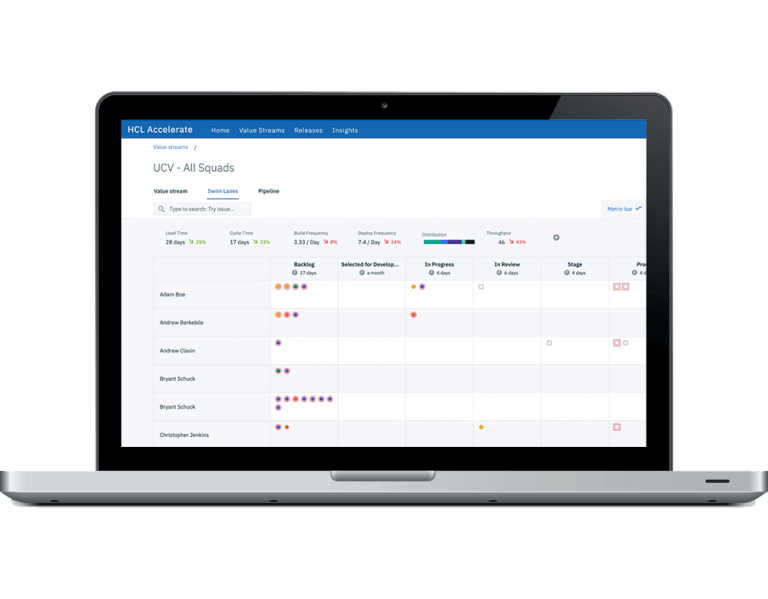
HCL Accelerate のSwim Lanes ビューでは、チームの仕事の全体像を把握できます。
このブログシリーズでは、データが組織内で果たす重要な役割について見ていきます。特にコアとなる「影響を与える領域」と、データがどのようにDevOpsの主要な会話に影響を与えることができるかに焦点を当ててみたいと思います。
- 人: データを通じたDevOpsの人間化
- プロセス: データを使ったトラッキングとプランニング
- テクノロジー: データ主導のビジネス・アジリティ
データに基づいて DevOps イニシアチブを推進することは、最終的には、個々の貢献者の努力がビジネス目標と明確に一致するような、より共感性の高い DevOps 組織を育てることにつながり、プロダクト・マネージャーは、何がデリバリーのために計画されているのか、何がリスクであり、何を残す必要があるのかを利害関係者や顧客に簡単に伝えることができるようになります。データを DevOps の目標の最前線に持ってくることで、組織全体として、リスク、コスト、収益をより良く管理することができるようになります。 データ駆動型の DevOps とバリュー・ストリーム管理が、組織におけるDevOpsの話を変え、効果的な変化を実感できるようにするために役立つ多くの方法を、今後数週間にわたってご紹介していきます。
HCL Launch によるメインフレーム展開プロセス
2020/9/29 - 読み終える時間: 4 分
Mainframe Deployment Process with HCL Launch の翻訳版です。
HCL Launch によるメインフレーム展開プロセス
2020年9月28日
著者: Elise Yahner / HCL
HCL Launch は、メインフレームからモバイルまで、すべてのプラットフォームにデプロイできるエンタープライズワイドなデプロイツールです。IBM IでRPGプログラムをデプロイする場合でも、IBM ZでCOBOLをデプロイする場合でも、分散システムにJavaをデプロイする場合でも、そのすべてを HCL Launch を介して行うことができます。
z/OS のデプロイには、いくつかの特定のカスタマイズが必要であることは理解しています。HCL Launch は、z/OS で非常に一般的なインクリメンタルバージョンをサポートしています。HCL Launch は、バージョンをマージしたり、デプロイ時間を短縮するための成果物のデルタデプロイを行ったりすることをサポートしています。HCL Launch は、環境にデプロイされたバージョンを見つけるために、アーティファクトの検索をサポートしています。
HCL Launch は、成果物のパッケージングを支援します。HCL Launch には、 z/OS の成果物をパッケージ化するためのbuzztoolと呼ばれるユーティリティがあります。
このブログでは、シンプルなメインフレームのデプロイメントプロセス設計についてお話します。メインフレームのデプロイメントのためのシンプルなコンポーネントプロセス設計は、以下のステップを持っています。
- z/OS 用のアーティファクトをダウンロードする。
- データセットのデプロイ
- アーティファクト情報の生成
- DB2 DBRMをバインド
- ニューコピーCICSリソース
- トークンの置き換え
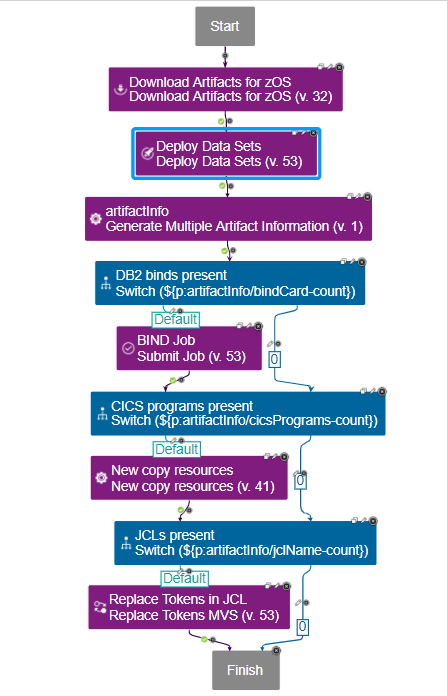
z/OS 用のアーティファクトをダウンロードする
このステップでは、デプロイするバージョンのアーティファクトを Launch の内蔵アーティファクト・リポジトリ ? Codestation からターゲットのメインフレーム LPAR にダウンロードします。アーティファクトをArtifactoryやNexusなどの外部アーティファクト・リポジトリに保存している場合は、このプラグインを使用してターゲットのメインフレームLPARへのダウンロードを行うことができます。
通常、このステップでは、設定するための特別な入力は必要ありません。
データセットの配置
このステップでは、ターゲット・メインフレームLPARのUSSフォルダ/PDSメンバーにデプロイします。前のステップからダウンロードした成果物と、ステップのプロパティで提供されたDatasetマッピングを使用して、それらをターゲット・データセットにマッピングします。
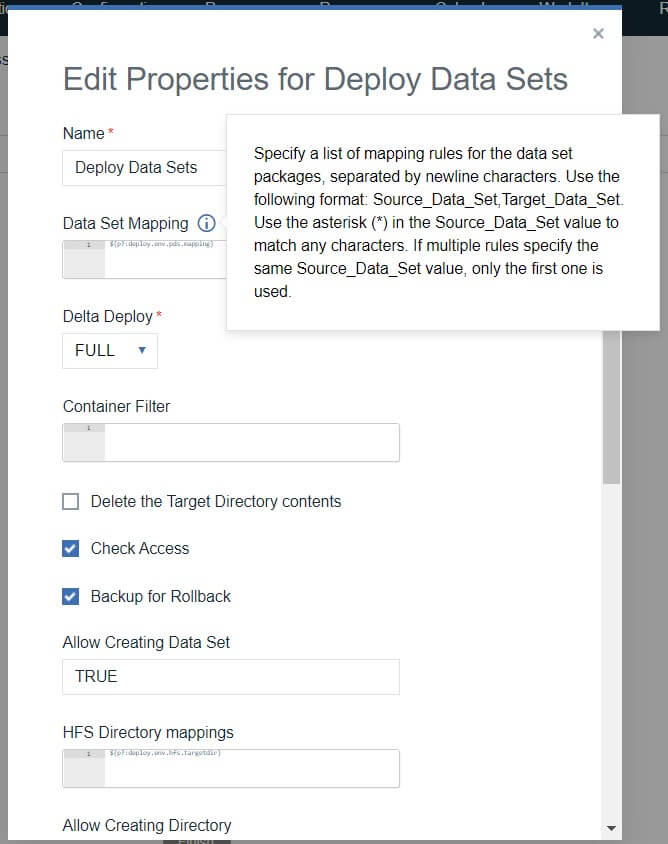
通常、Datasetマッピング (およびデプロイメントプロセスの他の多くのプロパティ) は、環境プロパティとして構成されます。このようにして、新しいターゲット環境が作成されたときに、これらの環境固有のプロパティを環境レベルで定義することができます。
データセット マッピングのサンプルを以下に示します。これは、source_pds , target_pds の形式です。source_pdsは、buztoolを使用してバージョンを作成する際にシップリストで使用されたPDS名です。これらは開発環境の pds 名です。これらは、HCL Launch UIでバージョンを見たときに表示される名前です。(Components -> YourComponentName -> Versions -> YourVersionName) となります。Target_pds は、デプロイが必要なこの環境の pds 名です。

Deploy datasets には "Backup for Rollback" のフラグがあります。チェックを入れると、このステップでは、デプロイ前に置き換えられる予定の現在のPDSメンバーがバックアップされます。この内蔵のバックアップ/ロールバック機能は、HCL Launch Mainframeプラグインに特有のものです。バックアップはターゲットLPARのUSSに保存され、必要に応じて "Rollback Dataset "ステップで使用されます。
ターゲットLPARにデータセットがまだ存在していない場合、プラグインがデータセットを作成できるようにするデータセット作成を許可するように設定できます。
アーティファクト情報の生成
PDSへのデプロイが完了した後、通常、バインド、ニューコピーなどのデプロイ後のステップがあります。このステップは、デプロイ後のプロセス(例えば、バインド)を経る必要があるアーティファクトを特定するのに役立ち、また、テンプレートからそれぞれのアーティファクトのためのコマンド(例えば、バインドカード)を生成します。異なるアーティファクトのセットに対して複数のコマンドを生成できる新しいプラグインがあります。
このステップでは、ソース PDS 名 (コンテナ名)、ターゲット PDS 名、デプロイタイプ、あるいは独自のカスタムプロパティを使用して、成果物をフィルタリングするのに役立ちます。
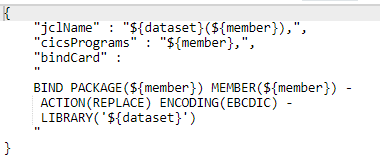
次に、以下に示すようなJSONテンプレートを提供し、異なるテンプレートを使用して異なる出力プロパティを生成することができます。これらの出力プロパティは、デプロイ後のステップで参照することができます。1つのステップから任意の数の出力プロパティを生成することができます。
ジョブのバインド
DB2 のバインドは、"Submit Job" プラグインのステップでジョブを投入し、前のステップで生成されたバインドパラメータを使用して行われます。
CICS のNewcopy
CICS の Newcopy は、CICS TS プラグインと上記で生成された CICS プログラムのリストを使用して行われます。
トークンの置換
通常、メインフレームのデプロイメントでは、${HLQ}をその環境の高レベル修飾子に置き換える必要がある場合があります。例えば、JCLの場合。JCLのテンプレート化されたバージョン (あるいはDB2のDML文のような他の成果物) をSCMに格納することができます。そして、各環境は、アプリケーション環境プロパティに HLQ/DB2 スキーマ名を設定することができます。
このステップでは、デプロイ後のターゲット環境のすべてのトークンを、その環境固有の値に置き換えることができます。これにより、テンプレート化されたバージョンをSCMに保存し、デプロイツールに環境固有の値を置換させることが容易になります。
スイッチのステップ
上記のプロセス設計の中で、スイッチのステップがあることに気づいたかもしれません。これらのステップは、プロパティ値に基づいてどのパスを取るかを決めるのに役立ちます。このケースでは、バインドするものが何もない場合に、Bind のような展開後のステップをバイパスするためにスイッチ・ステップを使用しています。
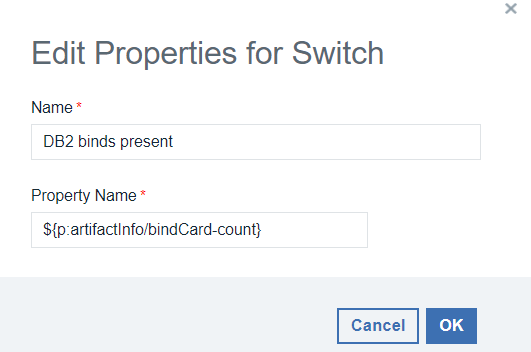
Generate Artifact ステップは、出力プロパティごとにカウント変数を生成します。bindCardのカウントが0以外の場合、バインドステップが実行され、それ以外の場合はスキップされます。これは必要なければ、デプロイ後の多くのステップをスキップするための優れた方法です。
HCL Launch でプラグインを設定する際にヘルプが必要ですか。サポートチームに連絡してください。
Unica: メールマーケティングオートメーションで成果を出すための 5 つの重要な理由
2020/9/25 - 読み終える時間: 6 分
5 Essential Reasons to Deliver Results with Email Marketing Automation の翻訳版です。
メールマーケティングオートメーションで成果を出すための 5 つの重要な理由
2020年9月24日
著者: Gordon Patchett / Product Manager for Unica Deliver

メールマーケティングは進化を続けていますが、今でもキャンペーンを実行するための最も効果的なチャネルのひとつです。今日の顧客は、顧客のニーズや行動に合わせてカスタマイズされたユニークなメールコミュニケーションを求めています。マーケッターは、同じ作業を何度も繰り返すことで貴重な時間とエネルギーを失うことなく、どのメールをどのタイミングで、誰に送るかを決定できる仕組みが必要です。一言で言えば、これがマーケティングオートメーションなのです。
デジタルコミュニケーション戦略において、なぜメールマーケティングが重要なのか?
現代のビジネスにおけるデジタルマーケティングの重要性を示す統計は数え切れないほどありますが、古き良き時代のメールには、特に豊富な統計があります。例えば、世界では約56億件のアクティブなメールアカウントが存在し(Statista、2019年)、そのうち3.9件が毎日利用されている(Statista、2020年)。セグメンテーションとターゲティングを利用しているマーケッターは、収益が760%も増加していることに注意している。Campaign Monitor, 2019)では、メールは費用対効果が高いだけでなく、収益性も高いとされています。
テクノロジーの観点から見ると、メールはほとんど変わらない一方で、私たちがメールを開いたり読んだりするために使用するデバイスは劇的に変化しています。モバイルでの開封が開封の46%を占めている(Litmus.com 2018)。これは、私たちのかなりの割合の人にとって、私たちは今でも外出先で、信じられないほどの規模でメールをチェックしたり読んだりしていることを意味しています。
理解できるように、最も開封されたメールは趣味に関連したものである(MailChimp, 2018)が、これは私たちが興味を持ったり、興味を持ったりする分野を調べるために時間を取ることに満足していることを示している。さらに、関連性のあるコミュニケーションは受信者に歓迎されます。ヨーロッパのGDPRは、送信者にゲームを上げて、自分たちが顧客に送るものが魅力的で、関連性があり、そして何よりも重要なのは、顧客が明確に望んでいるものであることを確認することを余儀なくされています。

メールマーケティングとは?
メールマーケティングでは、マーケティング担当者はパーソナライズされたコンテンツを作成し、関連性の高いオーディエンスにターゲットを絞ることができます。効果的なメールマーケティングツールを使用することで、ユーザーは以下のことが可能になります。
- 費用対効果の高いカスタマージャーニーの構築
- 時間と予算の最適化
- ITへの依存度を減らし、ROIを向上させます。
- 反復的なタスクの自動化
- データとクリエイティブなコンテンツを簡単に統合することができます。
- グローバルな視聴者にリーチ。
- Webサイトのトラフィックを生成します。
- アンケートを通じたフィードバックの収集
- 権威を確立し、高い顧客エンゲージメントを促進し、強力な顧客関係を構築する。
- ブランドの認知度を高める。
- 高いコンバージョン率を利用する。
- 法律(例えば、GDPR)内での作業
メールマーケティングの力を過小評価するのは危険です。メールマーケティングは、今も昔も、そしてこれからも、マーケティング担当者が利用できる最もコスト効率の高いチャネルです。そのため、マーケティング業務に適したプラットフォームを購入することは、ビジネス上の最も重要な決定事項のひとつであることに変わりはありません。
マーケティングオートメーションとは?
毎週のニュースレターやメールキャンペーンを作成して一度に大勢の人に送ることは別としても、ユーザーが何か行動を起こすたびに手動でメールを送信するのは非効率的で退屈な作業です。マーケティングオートメーションが解決策です。これにより、タスクを実行し、優先順位をつけ、効率的に合理化することができます。マーケティング担当者は、顧客の購買プロセス全体を中心に戦略を立て、どのようなオファーやメッセージが顧客の心に響き、購買に結びつくかを考えなければなりません。
そして、マーケッターはメールマーケティングに頼って成果を上げています。メールキャンペーンを自動化することで、タイムリーでパーソナライズされた、読者との関連性が高いメールを送ることができるようになります。あなたのメールキャンペーンのマーケティングオートメーションを活用する理由を見てみましょう。
メールキャンペーンで自動化機能を活用する 5 つの理由
-
マーケティング業務のコストを下げる。繰り返しのタスクにはコストがかかります。マーケティングオートメーションプラットフォームに投資することで、マーケティング担当者が何度も何度も定期的に行っていることに気づくタスクをすべて排除するチャンスが得られます。もしあなたが何かを頻繁に行っているのであれば、テンプレート、巧妙なコンテンツコネクター、ハイパーパーソナライゼーションを使用して自動化の候補となります。
-
一貫性をもって顧客体験を向上させる。今の時代、時間は貴重な商品です。例えば、ポイントカードの残高など、顧客に定期的に情報を提供する場合、自動化の方法を採用することで、一貫性のある信頼性の高い情報伝達方法を作成することができます。自動化によって、カスタマージャーニー全体でのコミュニケーションやゴールベースのマーケティング活動を迅速かつ簡単に実施することができます。つまり、顧客との新しいタッチポイントを導入する際に、一貫した体験を提供しながら、新しいサービスを導入することで、顧客の生活をよりシンプルにすることができます。
-
一貫したターゲティングとトラッキングによるデータ品質の向上 - データはマーケッターの通貨であり、優れたデータ品質は、より良いリーチと強化された顧客体験を提供するために不可欠です。自動化機能を使えば、同じコミュニケーションの自動化されたメールを何通も送信することができます。
-
一貫したターゲティングとトラッキングによるデータ品質の向上 - データはマーケッターの通貨であり、優れたデータ品質は、より良いリーチを実現し、顧客体験を向上させるために不可欠です。自動化により、特定の行動に基づいてさまざまな顧客セグメントに同じコミュニケーションの自動化されたメールを連続して送信することができ、マーケティング戦略をスケーラブルにすることができます。また、データ収集の改善により、マーケティングリソースに追加的な要求をすることなく、次にどのようなメッセージを送信すべきかを具体的に把握するシステムを構築することができます。
-
反復作業を減らして仕事を充実させる- 反復は必ずしも創造性の敵ではありません。例えば、楽器を演奏することは、筋肉の記憶を呼び覚まし、演奏方法よりも何を演奏したいかに集中するための練習と反復に依存しています。しかし、充実感は単調さから生まれないことは誰の目にも明らかです。マーケッターが単調にならないようにして、目的を達成するための障害を減らすことができれば、マーケッターはより生産性を感じ、最終的にはより多くの成功を収めることができるでしょう。技術的な障害による負担が少ないチームは、より幸せであり、より輝ける可能性が高くなります。
-
イノベーションを追求するためにマーケティングチームを解放する - その中核には、マーケティングはイノベーションについてでなければなりません。それは、顧客の立場に立ち、消費者の行動を理解し、新しいテクノロジーに適応することである。自動化によって、マーケティング担当者はこれらのコアポイントに注意を集中し、顧客との関係をどのように成長させることができるかについて、より深い理解を深めることができるようになります。

Unica Deliver とは?
ここまで、メールマーケティングの自動化とは、最小限の手作業でパーソナライズされたカスタマージャーニーを作成することであることを示してきました。これを実現するためには、同じ単一のUIでデータとコンテンツをシームレスに扱うことができ、多くの異なるチャネルと簡単に統合できる製品が必要です。
Unica Deliver は、メールや SMS などのチャネルを横断して、シームレスでパーソナライズされたタイムリーなコミュニケーションを提供するためのデジタルマーケティングソリューションです。あなたは簡単にあなたのブランドのメールテンプレートを設計し、セグメントし、あなたのメールリストを管理し、リードを育成し、あなたの休眠中のクライアントと再エンゲージすることができます。また、Campaign、Interact、Journey などの Unica Suite の他のツールとシームレスに統合されています。
デジタルマーケティングオートメーション @ Scale: Unica Deliver のご紹介
Unica Deliver は、信頼性が高く、拡張性があり、シームレスに統合されたデジタルメッセージングソリューションであり、メール、SMSなどのチャネルを介して、タイムリーでパーソナライズされたコミュニケーションを提供します。
我々はより詳細にステートメントを掘り下げれば、我々は、プラットフォームがあることを理解し始めています。
- 信頼性と拡張性 - このプラットフォームは、年間数百億通のメールを送信することができます。
- スイートの残りの部分とシームレスに統合 - 顧客やコンサルタントを混乱させるようなミドルウェアのコンポーネントはありません。それはただ動作します - あなたが期待しているように、自動的に、何の騒動もなく。
- チャネル - 私たちは、エコシステムを構築しており、それを実現できるだけ早く、より多くのデジタルチャネルを追加しています。
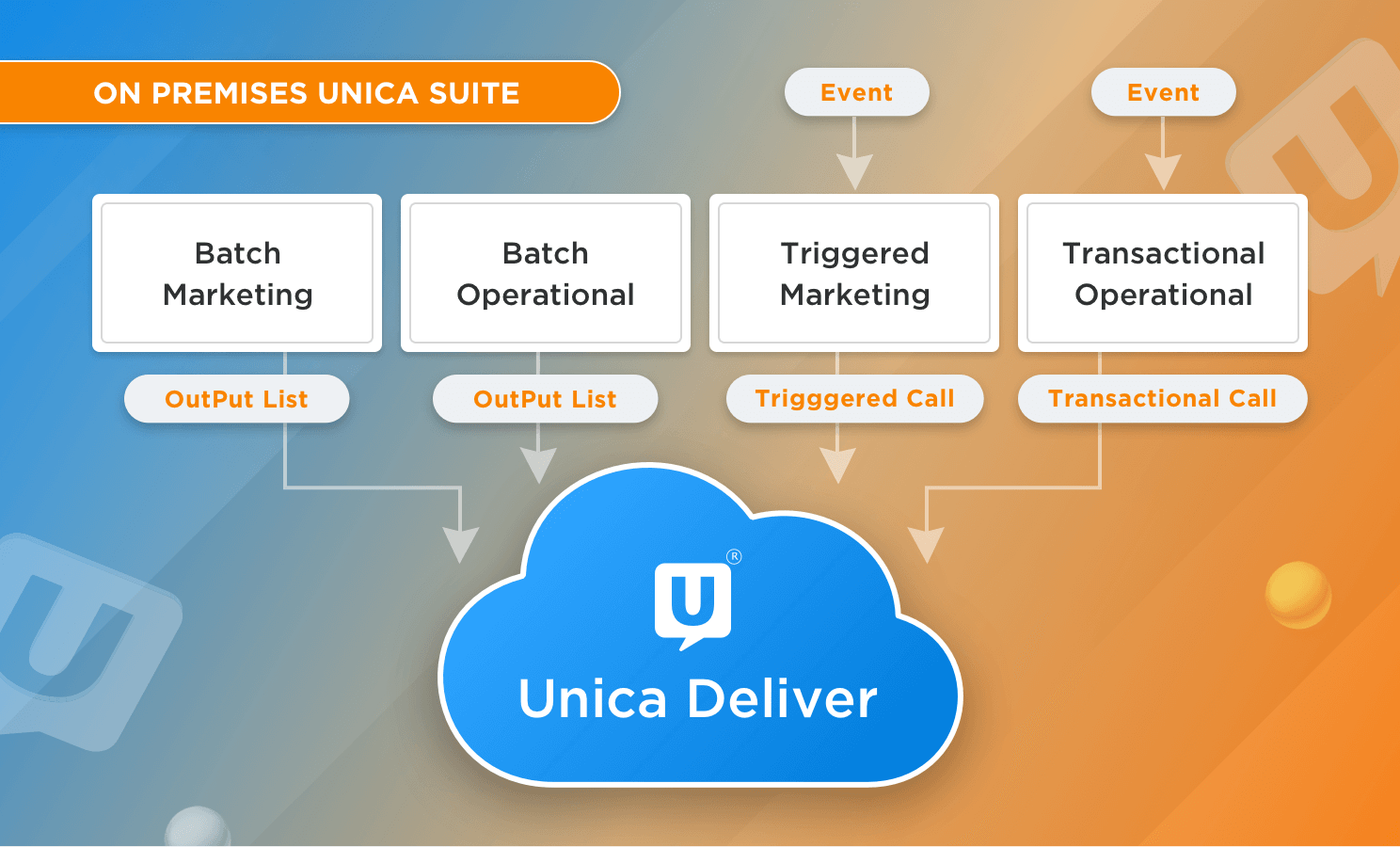
Deliver エコシステムが提供するスケーラビリティーとマルチチャネル統合機能の詳細については、Unica Deliver の紹介ビデオをご覧ください。
Deliver ではどのように動作するのか
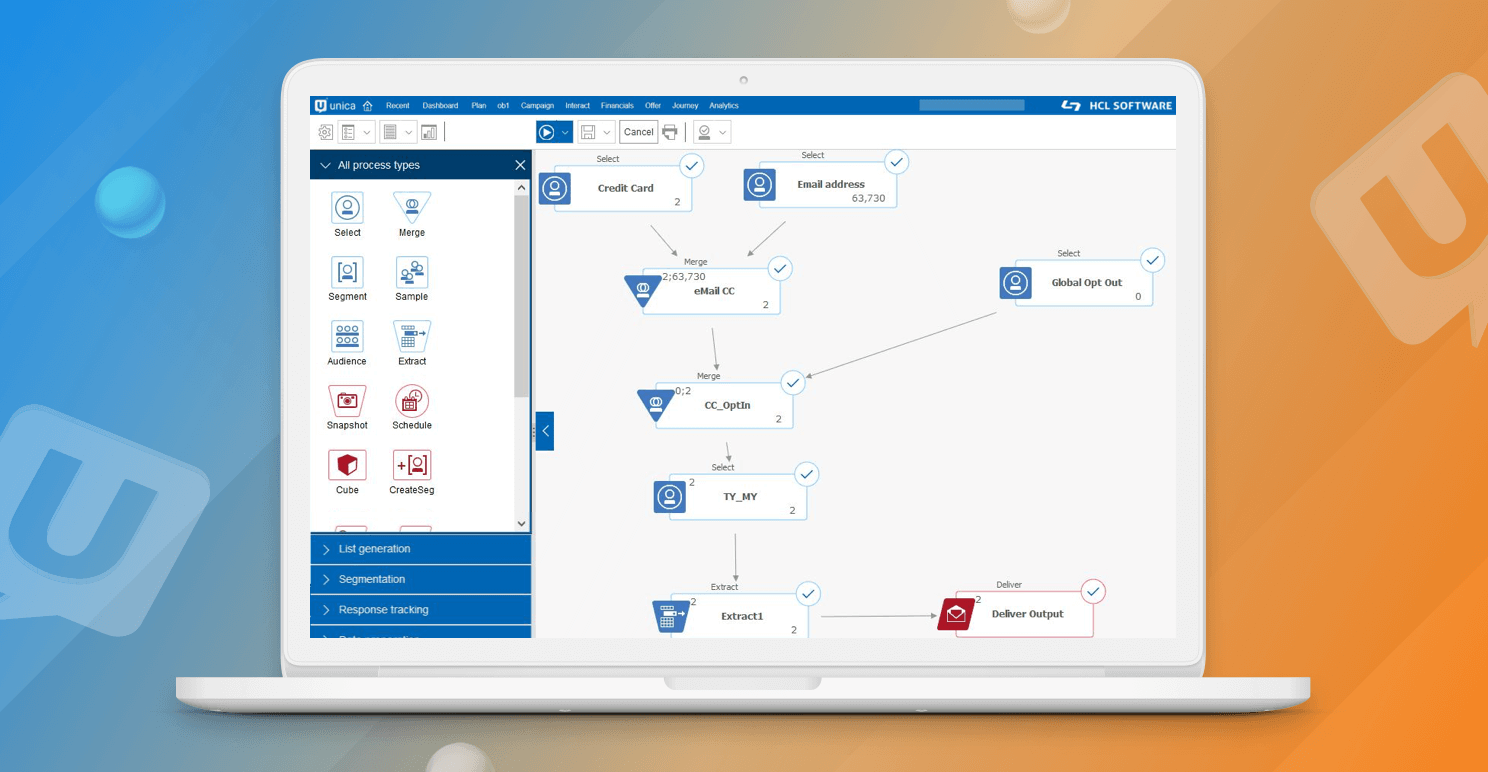
まず、Unica Campaign でキャンペーンとオファーを作成し、必要なコンテンツとパーソナライゼーションを考えます。次に、キャンペーンフローチャートを作成してマーケティングデータを定義し、Deliver 出力リストを作成します。
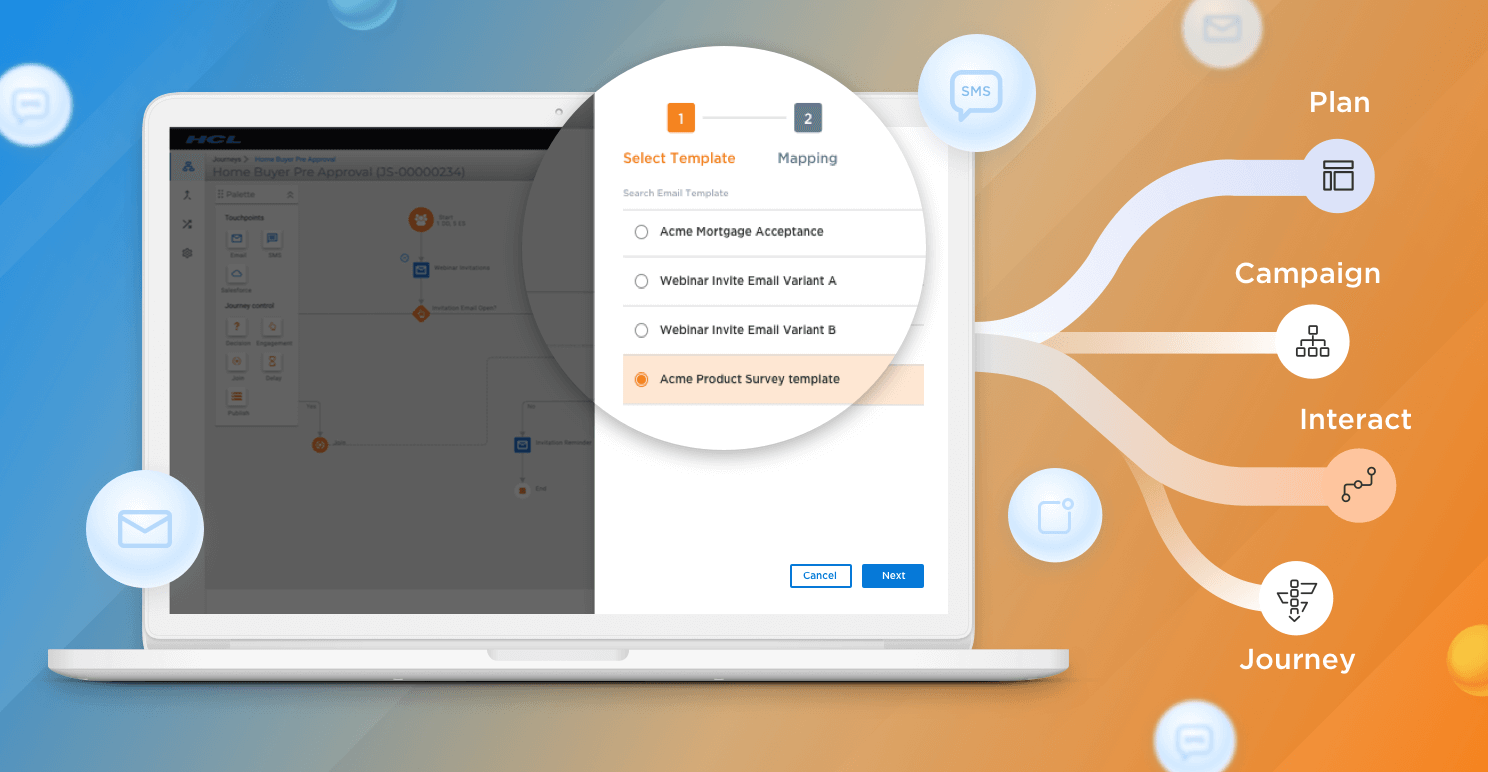
次に、必要なコンテンツを Unica Deliver にインポートします。
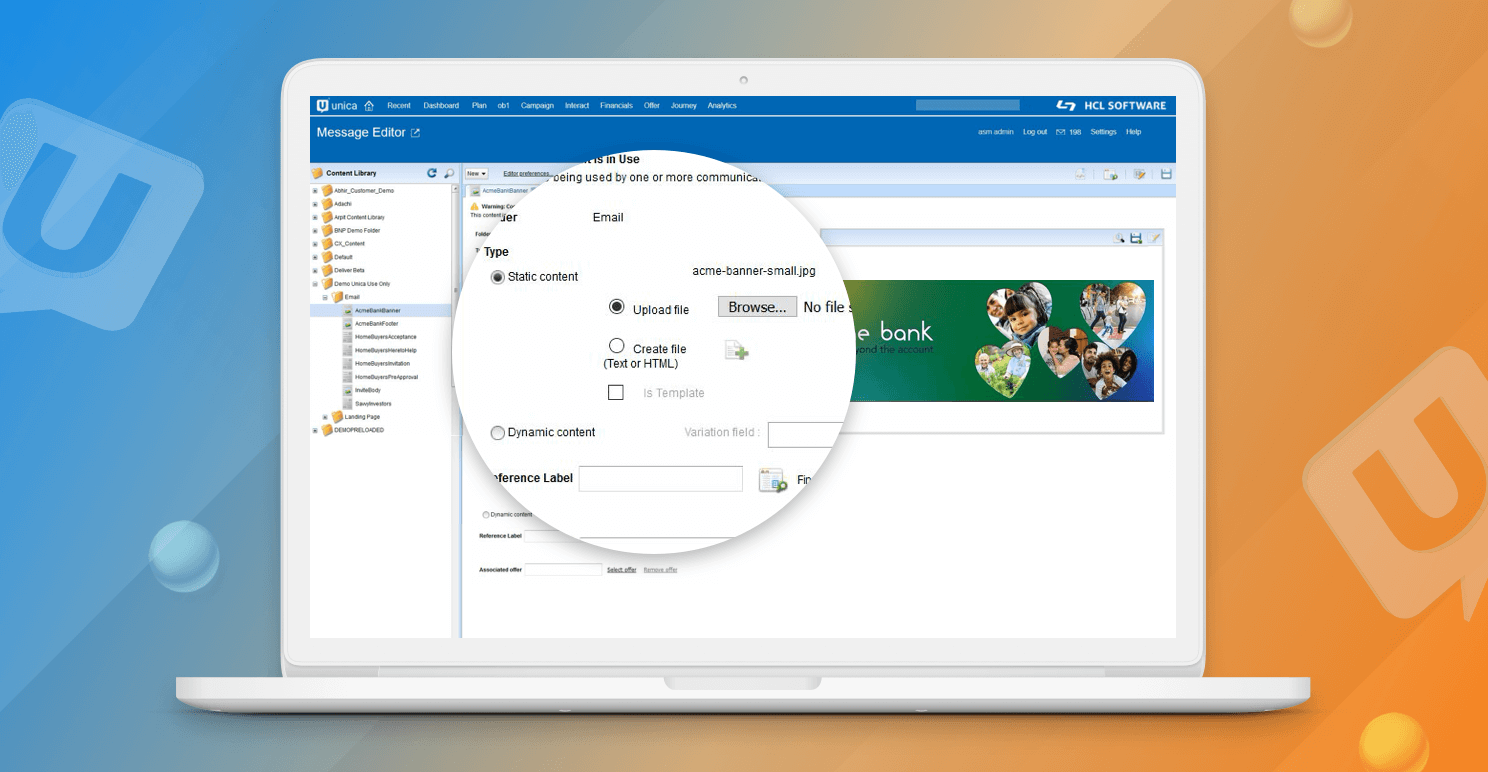
次のプロセスでは、シンプルな Deliver コミュニケーションを作成し、インポートしたコンテンツをゾーンにドラッグして、誰に何を表示するかを定義するためのルールを作成します。
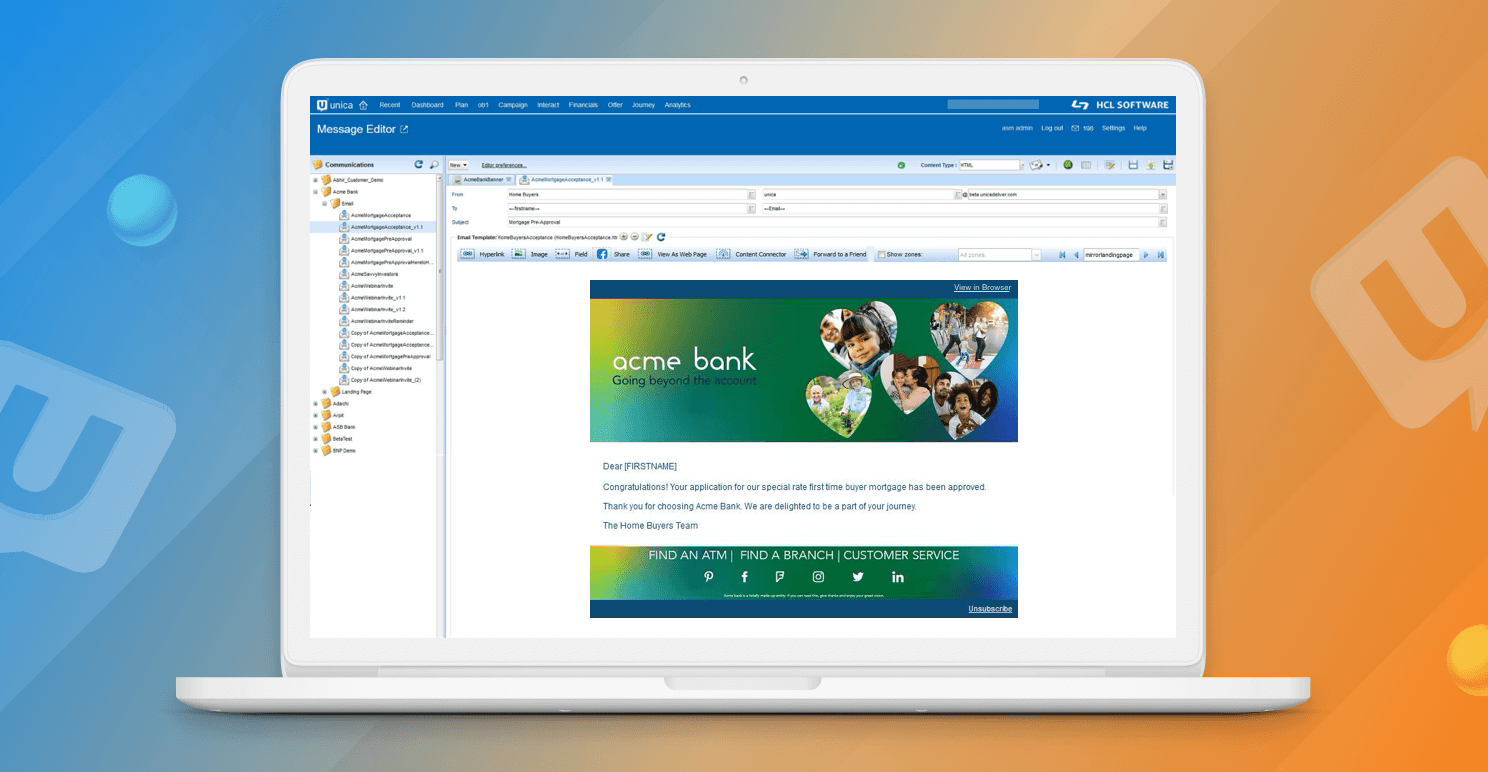
ワークフローの次の部分は、出力リストテーブルを通信に結びつけるためのメーリングリストを作成し、メーリングリストを実行します。メーリングリストのスケジュールはキャンペーンフローチャートにリンクさせることができるので、データの準備が整い次第、メッセージが送信されます。

そして最後に、レスポンスはシステムのテーブルにフィードバックされ、レポートを実行することができ、キャンペーンの結果を分析することができます。
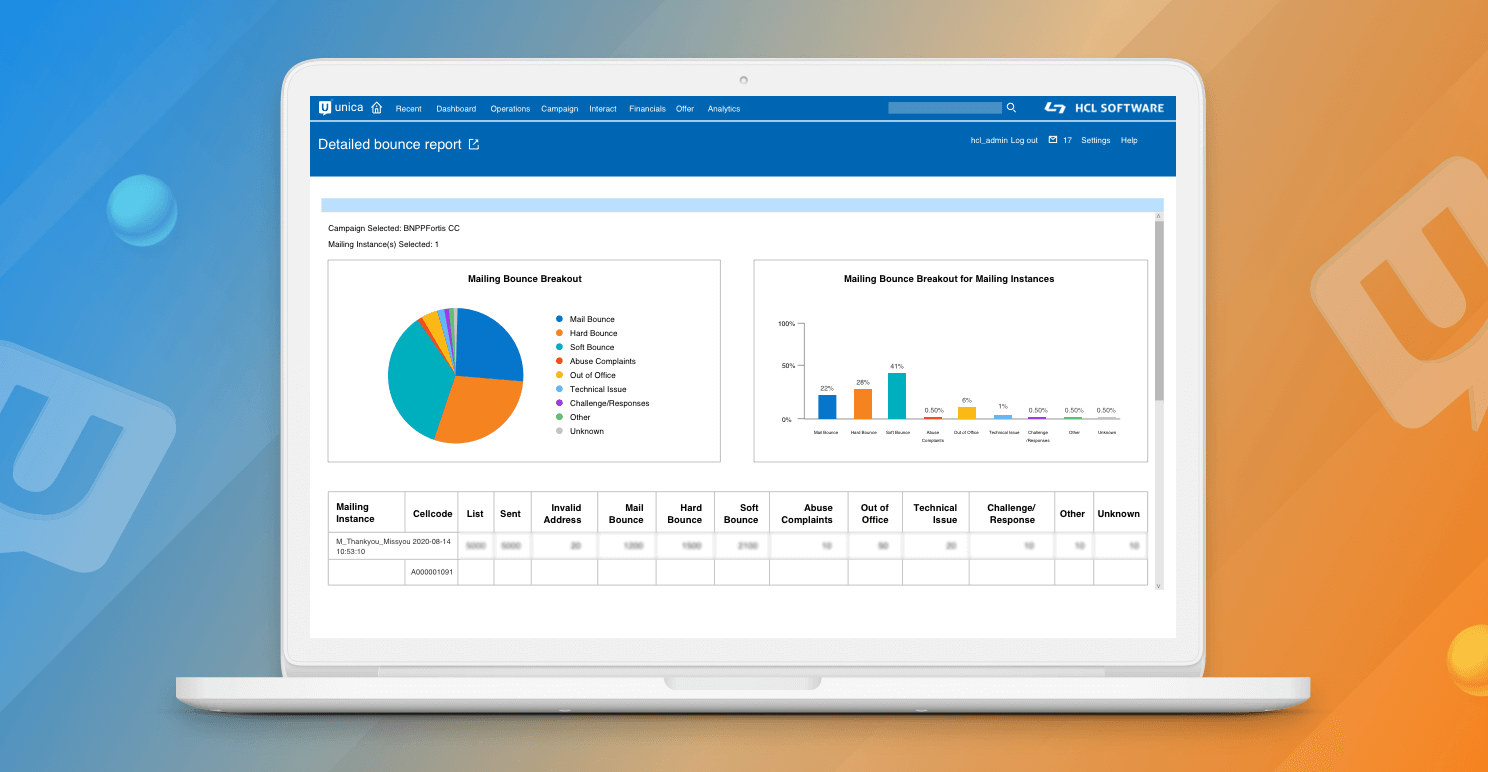
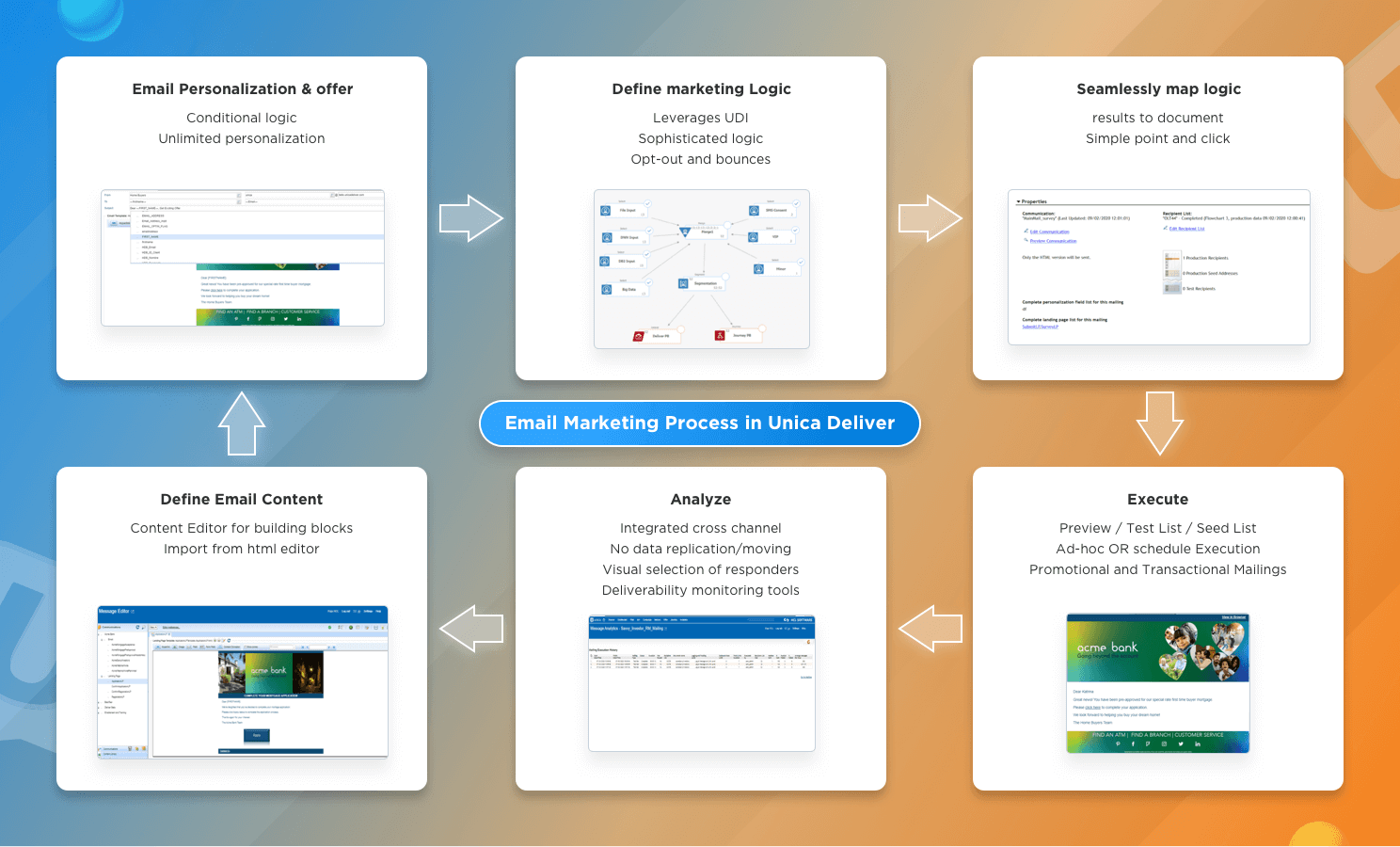
簡単に説明すると、以下のようになります。
- キャンペーンフローチャートは、出力リストテーブルまたはOLTを作成します。
- メールデザイナーがコミュニケーションを作成
- OLTと通信を連携させるためのメールが作成される
- と受信者に送信されます。
- 最後に、連絡先と回答のデータは、キャンペーンの結果を表示するためにレポートにフィードバックされます。
この基本的な設定が完了したら、通信を繰り返すための自動化の機会を探るべきです。Deliver には、さまざまなユーザータイプに合わせた作業方法があります。
ドラッグ&ドロップによるルールビルダー機能により、ユーザーはツールを使ってすぐに作業を始めることができます。ユーザーが自信を持てるようになると、高度なスクリプトを利用して、入れ子になった条件付きルールセットなど、より複雑なルールセットを構築することができます。これらの機能はすべて、単一のUnicaインターフェースでUnicaプラットフォームとシームレスに統合されています。
なぜ Deliver は Unica Suite のゲームチェンジャーなのか
ドラッグ&ドロップによるルールビルダー機能により、ユーザーはこのツールを使ってすぐに作業を始めることができます。ユーザーが自信を持てるようになると、高度なスクリプトを利用することができ、入れ子になった条件付きルールセットなど、より複雑なルールセットを構築することができます。これらはすべて、単一のUnicaインターフェースでUnicaプラットフォームとシームレスに統合されています。
Deliver がUnica Suite のゲームチェンジャーとなるのはなぜでしょうか
Unica Campaign と Unica Deliver は、シングルステップでシームレスに統合されています。必要なものはすべて、単一のUIに含まれています。データの抽出や転送の心配はありません。また、回答はプラットフォームで直接収集されるため、ミドルウェアのコンポーネントを使用して障害点を追加したり、テクニカルサポートプロセスを複雑にしたりする必要もありません。これにより、マーケティング担当者は、テクノロジーとの戦いではなく、重要なことに時間を割くことができるようになります。
- 無料のオンボーディングと配信サービス
Unicaは、メール業界で認められたチームへのアクセスを提供しており、業界全体で協力してISPやメールクライアントを理解し、メールを受信箱に入れて迷惑メールフォルダーに入れないようにする方法を理解しています。他の多くのプロバイダーはこのサービスを有料で提供していますが、当社は無料で提供しています。メールボックスの配置の重要性は当然のことながら、当社との連携により、可能な限りのご案内をさせていただくことを期待しています。
- メールの超過料金
Unica Deliver では、お客様に超過料金を請求することはありませんので、隠れたサプライズのない効果的な予算編成が可能です。万が一、お客様が超過料金を請求された場合でも、当社のアカウントマネージャーがお客様と協力して、来年の予算が予想外に膨らむことのないよう、効果的な予算編成のお手伝いをさせていただきます。
- 容量
Unica Deliver は、大量のメールを送信することを念頭に置いて一から設計されており、多くの競合他社が当社の送信数に近づけようと苦労しています。
- 柔軟なメールの長さ
Unica Deliver は、ひとつから多数の関係を素早く簡単に表現できるテンプレートを作成することができます。異なる行数に対応するために、複数のメールテンプレートが必要ですか? Unica Deliver では、これらのテンプレートをすべてひとつのテンプレートにまとめることができ、表示する必要のあるレコード数に応じて行数を変化させることができます。
- 安定性
Unica Deliver は、信頼性を重視して設計されています。99.9%のアップタイム目標を掲げ、重要なコミュニケーションを送信する必要がある場合にはいつでも Deliver をご利用いただけます。
時間をかけて自動化を行えば、マーケティング運用コストを削減して効率化を実現し、収益性を高めることができます。あなたのコミュニケーションに一貫した外観と感触を与えることで、購読者は満足することでしょう。データの質が向上して標準化され、分析の幅が広がります。そして何よりも重要なのは、チームがより幸せになり、より革新的になることです。
一言で言えば、マーケティングオートメーション機能を活用する5つの理由は以下の通りです。
- マーケティング業務のコスト削減
- 加入者ベースに一貫したサービスを提供する
- 一貫したターゲティングとトラッキングによるデータ品質の向上
- あなたのマーケティングチームを解放し、イノベーションを追求する
- 反復作業を減らすことで仕事を充実させる
デジタルマーケティング戦略を次のレベルに引き上げる方法の詳細については HCL Software にお問い合わせください。また、製品の詳細な洞察を得られる、Unica Deliver の Deep Dive ウェビナーを視聴できます。
BigFix でパッチコンプライアンスを維持して危機を回避する
2020/9/24 - 読み終える時間: 2 分
Avoid a Crisis, Stay in Patch Compliance with BigFix ! の翻訳版です。
BigFix でパッチコンプライアンスを維持して危機を回避する
2020年9月23日
著者: Ben Dixon / HCL

9月18日に DHS が CVE-2020-1472 を対象とした緊急指令を発表したとき、多くの人々の注目を集めました - DHS が各機関に脆弱性のあるシステムへのパッチ適用を要求したのではなく、パッチ適用までの道のりが非常に短い(96 時間未満)ということです。実際、この脆弱性は1ヶ月以上前に発見され、マイクロソフトは 8月11日にパッチをリリースしました。では、なぜ 1ヶ月後に指令が出され、なぜエンドポイントがすでに CVE に対応していなかったのでしょうか?なぜなら、何ヶ月も、場合によっては何年もパッチが適用されないままになっているエンドポイントはたくさんあるからです(平均は 200日程度)。
脆弱性のスキャン
ステップ 1 は、明白なものです:環境の脆弱性をスキャンし、脆弱性スキャナの結果に注意を払います。ほとんどの組織では、何らかのスキャナを採用しているので、スキャンを実行して結果を分析してください。しかし、スキャンはある時点で実行されるため、スキャン後に何が起こるかわからないということを覚えておいてください(毎月スキャンすると、CVE 2020-1472 のような脆弱性を見逃してしまうかもしれません!)。この問題を克服する方法について、もう少し詳しく説明します。
防衛の詳細
ステップ 2 は、おそらくかなり明白なことだと思いますが、仕事を確実にこなすために、複数のツールを持っていると良いこともあります。一見同じことをするように見えるツールを2つ持っていても何も問題はありませんが、それが異なる方法で行われている場合は特にそうです。例えば、月に一度は脆弱性スキャンを実行し、週に一度はパッチコンプライアンススキャンを実行するとします。いくつかの例外を除いては、ほとんど同じものを探していることになります。市場に出回っているすべてのセキュリティツールを購入する必要はありませんが、冗長性があることは悪いことではありません。
脆弱性への処方箋
これは簡単そうに見えても、実際には私たちを悩ませるものであり、CVE-2020-1472 に関する問題の核心をついています。DHS が CVE に準拠しているのであれば、適用されるすべてのエンドポイントにパッチが適用されていれば、DHS がこの指令を出すことはなかったでしょう。そして、これはセキュリティパッチであれ、設定項目であれ、何度もそうなっているようです。Microsoft や RedHat のようなベンダーがパッチを出してきたら、私たちはできるだけ早くパッチを適用する必要がありますが、その理由は次のとおりです:ソフトウェアベンダーは常に自社の欠陥を見つけられるわけではありません。そのため、パッチがリリースされたときには、すでに既知の脆弱性であり、脆弱性の説明も含まれており、しばしばエクスプロイトの説明も含まれていることがあります。それは、駐車したガレージで新車の鍵を失くしたようなものです。泥棒がしなければならないことは、フォブをクリックして少し歩き回り、車が「ここにいるよ!」と反応するのを聞くことです。
プロセス、変更管理、メンテナンスウィンドウなどがありますので、パッチを当てればいいという単純なものではありません。しかし、私たちはすでに知っている脆弱性を修復するために、より良い仕事をする必要があります。そして、一度脆弱性を修正したら、その脆弱性が修正された状態を維持するための仕組みが必要です。
では、手元にある脆弱性を確認し、脆弱性に対応し、その後も環境のコンプライアンスを維持するためには、他に何ができるでしょうか?
ツールセットに BigFix を追加する
そこで登場するのが BigFix です。BigFix は、IT セキュリティ・マネージャに脆弱性の継続的な可視性を提供し、IT オペレーション・チームが脆弱性に対応するために必要なツールを提供するセキュリティ・プラットフォームです。これにより、BigFix は、企業レベルだけでなく、すべてのエンドポイントで継続的なコンプライアンスを維持する能力を提供します。
BigFix は、パッチがインストールされているかどうかをチェックするだけでなく、脆弱性が存在するかどうかをチェックします。大規模な組織にパッチを適用するためにツールを使用したことがある人なら、すべてのパッチが最初から適用されるわけではないことを知っているでしょう。また、コンピュータの再起動が保留されている場合にパッチがインストールされない場合や、パッチがインストールされているように見えても実際にはインストールが成功していない場合もあります。BigFix を追加すると、パッチを展開するだけでなく、展開メカニズムの背後で脆弱性が本当に修正されたかどうかをチェックできます。
可視性のギャップに対処する
脆弱性対策の世界では、いくつかの可視性のギャップがあります。最初のものは、先ほども触れたように、脆弱性スキャンの直後に発生します。スキャン時に存在していた脆弱性を知ることはできますが、スキャンは時間のスナップショットであるため、その後に起こることは何もありません。
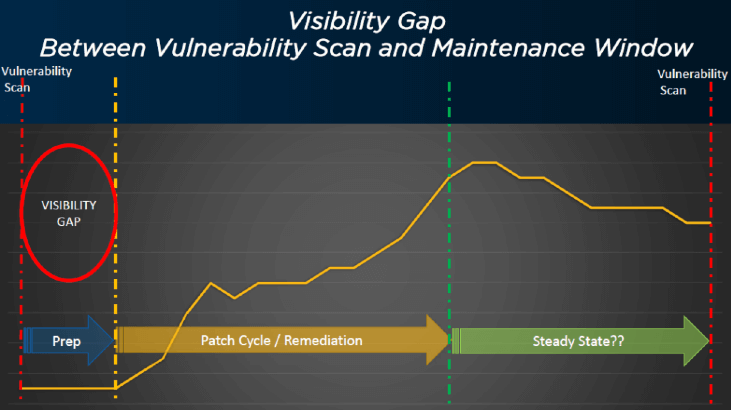
2番目の可視性のギャップは、運用チームが修復プロセスを実行している間に発生します。例えば、金曜日の夜にパッチ適用を開始し、日曜日の朝までにプロセスを完了させるとします。この間は目の前の仕事を達成することに集中し、進捗状況を評価するためにレポートを実行するために継続的に停止することはありません。
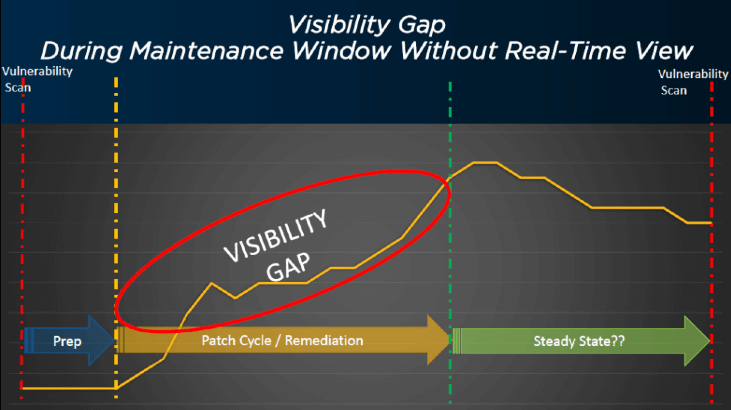
従来のポイント・イン・タイムのスキャン・ツールとは異なり、BigFix は、管理されているエンドポイント上でバックグラウンドで継続的に実行され、パッチを適用する際にステータスをレポートするスマート・エージェントに依存しています。BigFix は、メンテナンスウィンドウが終わるのを待ってレポートを実行し、どのような結果が得られたかを確認する必要はありません。
BigFix はまた、失敗したパッチを自動的に再試行したり、再起動が保留されているかどうかをチェックするパッチを適用するためにパッチサイクルの途中で再起動したりと、パッチ適用を細かく制御する機能も持っています。このようにして、BigFix は、何が起こっているのかを確認できるようにすることで、この可視性のギャップを埋め、改善プロセスの責任者を維持できます。
3番目の可視性のギャップは、メンテナンス・ウィンドウの終了から次の脆弱性スキャンまでの間に発生します。この間、通常、次回まで組織がコンプライアンスを維持するための仕組みはありません。これは、エンドポイントが非準拠になる原因となるようなことが起こるからです。ソフトウェアをインストールしたり、アプリケーションの設定を変更したり、設定項目を操作したりすることもあります。しかし、エンドユーザへの通知を行うか、次のメンテナンス・ウィンドウまで待つ以外には、通常、脆弱性に対処するメカニズムはありません。
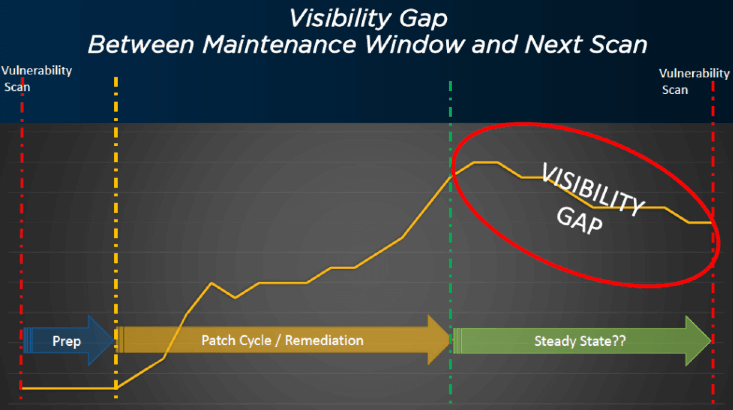
BigFix は、パッチ、設定項目、あるいはソフトウェアやアプリケーションの設定であっても、あなたが行った設定を強制する機能を持っています。エージェントは管理されているエンドポイントのバックグラウンドで動作するため、変更したくない設定を自動的に自律的に強制できます。そのため、誰かが想定外の設定を変更した場合でも、BigFix はそれを元に戻して変更します。誰かが必要なソフトウェアをアンインストールした場合は、BigFix が再インストールします。また、エンドポイントに何かが起きて、すでにパッチを当てているかもしれない脆弱性が再導入された場合、BigFix はその脆弱性が存在することを警告します。エンドポイントに再びパッチが適用されるようになった場合、BigFix を使ってパッチを再適用できます。あるいは、次のメンテナンス・ウィンドウや別の適切な時期まで待つこともできます。しかし、ここで重要なのは、あなたはそのことを知っているということです。次にスキャンしてレポートを実行したときに、驚くことはありません。BigFix があれば、それがわかるのです。
BigFix の動作
では、CVE-2020-1472をもう一度見て、この問題やその他の脆弱性の問題を BigFix がどのように解決できたかを見てみましょう。先に述べたように、これはDHSに対する攻撃ではありません。BigFix が環境にインストールされていれば、いつでも脆弱性を明確に把握できます。この情報がわかれば、BigFix やお好みのパッチ展開ツールを使って、脆弱性を修正するためのパッチをインストールして行動を起こすことができます。修正の進捗状況をリアルタイムで一目で確認できるため、プロセスの責任者としての役割を果たすことができます。また、パッチが配布されて適用された後は、修正された構成を強制的に適用できるので、環境をそのままにしておくことができます。やり直しや後戻りはありません。
エンドポイント管理ツールが機能しているように見える環境でも、先に説明した可視性のギャップを発見した場合でも、BigFix がツールセットに追加して、正しいセキュリティ姿勢を維持するのに役立つものを見てみませんか。可視性、レスポンス、およびエンフォースメント - コンプライアンスの姿勢を強化するための3つの優れたツール。環境に変更を加えるのはあなただけだからです。 BigFix の詳細については BigFix の Web ページをご覧ください。
Search
Categories
- Aftermarket Cloud (2)
- AppScan (178)
- BigFix (198)
- Cloud (14)
- Cloud サービス (1)
- Collaboration (625)
- Commerce (23)
- Customer Data Platform (1)
- Data Management (3)
- DevOps (223)
- Domino (1)
- General (237)
- News (11)
- Others (4)
- SX (1)
- Total Experience (13)
- Unica (171)
- Volt MX (75)
- Workload Automation (18)
- Z (48)