HCL AppScan: 継続的なセキュリティの強化
2020/8/25 - 読み終える時間: 2 分
セキュリティーにまつわる、AppScan シリーズの 3 回目です。HCL AppScan: Intensify Continuous Security の翻訳版です。
HCL AppScan: 継続的なセキュリティの強化
2020年8月24日
著者: Rob Cuddy / HCL

第 1 回目のブログ「継続的セキュリティ」では、3 つのテーマ分野の概要を説明しましたが、それぞれに 2 つの重要な能力が含まれています。このシリーズの第 3 回目のブログでは、「Intensify」というテーマと、「Educate」と「Govern」の能力に焦点を当てています。
継続的セキュリティに関連するテーマに「強化」という言葉を使うのは変だと思われるかもしれません。結局のところ、「激化」という言葉を調べてみると、その定義は簡単に言うと、"become or make more intensify"となります。
では、どのような意味でしょうか。
多くの組織が DevOps のプラクティスを採用している、あるいは採用中であり、それらのプラクティスにセキュリティを組み込むことにも取り組んでいます。これは素晴らしいことなのですが、それだけの取り組みやプロジェクトではありません。パイプラインにセキュリティテストを追加し、結果を共有して「完了」と呼ぶようなものではありません。そうではなく、最初に行った努力を積み重ね、そこから学び、コース修正をしていかなければなりません。さらに、セキュリティチームを超えてセキュリティプログラムを拡大し、組織の開発プラクティスに組み込むことで、セキュリティプログラムを強化することも視野に入れています。
リスクを発見し、軽減する能力を継続的に向上させていく必要があります。要するに、強化するための取り組みは、アプリケーションをより健全に、そして時間をかけてより安全にするために行われているのです。
セキュリティを本当に継続的なものにするためには、セキュリティパラダイムを増幅して拡張する必要があり、その結果、より安全なコードが書かれ、より良いセキュリティプラクティスが守られるようになります。そのためには、より良い教育とより良いガバナンスが必要です。
教育
教育というと、いくつかの異なる側面があり、それぞれが重要である。教育はセキュリティプログラム全体を超越しており、セキュリティが開発、テスト、運用、セキュリティとどこで連携するかによってニーズが異なります。何よりもまず第一に、コードを書いて作業をしているチームのためのものです。
正直に言うと、開発者は通常、安全でないコードを書こうとしているわけではありませんが、何が本当に脆弱なのか、どのようにして悪用が起こるのかについての認識不足に悩まされていることが多いのです。開発者は一般的に、最初から安全なコードを作れるようになりたいと考えています。これには正式なトレーニングが必要になりますが、クラスと並行して開発者は、組織内のチームが実施した脆弱性修正のリポジトリなど、具体的で文脈に沿った例を必要とし、他の人がその恩恵を受けられるようにします。結局のところ、これだけ多くのコードが共有されているのですから、もしあなたが脆弱性に遭遇した場合、他の誰かが脆弱性を持っている可能性は十分にあります。このことは、理想的には、セキュリティプログラムのガバナンスと連携した安全なコーディングガイドラインに反映されるべきです。
組織におけるより広範なセキュリティプログラムを真に推進する明確なステップは、開発チーム内で独立したセキュリ ティチャンピオンを育成し、成長させることです。これを成功させるには、セキュリティ意識とベストプラクティスに関する教育が鍵となります。セキュリティチャンピオンを独立させ、セキュリティチームとの連携を強めることで、企業ベースのセキュリ ティポリシーと実践が確実に管理されるようになる。セキュリティチャンピオンは、より広いチームとして協力し、お互いに学び合うこともできます。
第二の側面は、ツールとプロセスに関するものである。DevOps が要求するペースを維持するためには、コーディング時に支援を提供できるツールを用意することが不可欠である。リリースサイクルの最後に重要なセキュリティ問題が特定され、修正に対応するためにピボットが必要になると、チームはイライラしてしまいます。それよりも、コードがコミットされたときにコードの健全性についての洞察を得ることの方がはるかに有益です。DevSecOps では、自動化と統合が非常に重要です。各チームは通常、微妙に異なる方法でアプローチしているため、ベストプラクティスと統合するための手順についての教育は非常に有益です。
そして、最後に取り組むべきことは予算です。より良く、より安全になるためには投資が必要です。トレーニングを受け、リスクを低減している人に報酬を与えることです。そして、それは単に良い習慣ではなく、実際にはビジネスの全体的な士気を高めることになります。Sonatype による最近の調査では、定期的にセキュアなコーディングトレーニングを受けている開発者は、仕事に満足している可能性が5倍高いという結果が出ています。
ここまで人の話をしてきましたが、次はプロセスの話をしましょう。
統治 (ガバナンス)
継続的セキュリティモデルでは、ガバメントは後回しにされていますが、実際には、セキュリティプログラムが始まるのはここからであることが多いのです。多くの組織がアプリケーションセキュリティを追求するのは、外部からのコンプライアンス要件からくるやむを得ない必要性があるためです。Payment Card Industry Data Security Standard (PCI DSS) やSarbanes-Oxley Act (SOX) は、一般的なコンプライアンスの推進要因の例であり、セキュリティガバナンスと整合性があり、最初の段階で優れた方向性を提供してくれます。課題は、継続的な改善と継続的なセキュリティという目標に到達できるように、プログラムを確実にその先に進めることです。
理想的な世界では、完全に柔軟なポリシーと実践があり、それが完璧に機能して、必要とされる卓越した運用を実現できるでしょう。方針と手順はビジネスの目標に沿ったものであり、自然と便利で安全な結果に向かって進んでいきます。
あまりにも多くの場合、私たちが持っているのは、多くのアラート、通知、監視、優先順位のジャグリングを生み出す、十分な量の自動化です。実際、CriticalStart が実施した 2019 年の調査では、セキュリティ担当者の 70%が1日に10件以上のアラートを調査しなければならないことがわかりました。受信するだけではなく、調査する 誰もが「左遷」する方法を模索している世界では、それらの調査には通常、開発チームが関与しています。そのような場合、35%がスタッフを増やそうとしているか、または大量のアラート機能をオフにしていることが同じ調査でわかりました。
これは、私たちが求めていたものとは正反対の結果です。
前述したように、適切なガバナンスはビジネスを可能にするものです。それはちょうど十分なルールを提供し、ポリシーの遵守、コンプライアンスへの対応、ビジネス目標の達成を確実にします。では、実際にどのようにしてそれを達成するのでしょうか。行動よりも結果を測定することから始めるのです。
簡単な例を挙げてみよう。休日の週末の金曜日の午後遅くです。コードはコミットされ、ビルドプロセスが実行されています。プロセスの一部には、新しいコードの変更を検証するためのセキュリティスキャンが含まれています。そして、それが起こります。クリティカルテストが失敗し、ビルドプロセスが開始され、メールが飛び交い始めます。次に何が起こるのでしょうか。
もしあなたが行動を測定しているのであれば、最初の質問は「いったい誰が悪いコードをチェックインしたのか」、「誰がコミット前にスキャンを実行しなかったのか」、「誰がそのライブラリを追加したのか」などです。この人が修正する必要がある人だという前提があるので、PERSONを見つけることに焦点が当てられています。
代わりに結果を測定しているのであれば、最初の質問はより可能性が高い"What?"です。何が悪かったのか」「何を見逃したのか」「どんなテストを行ったのか目標は、何が起こったのかを理解し、将来的にそれを防ぐことができるようにすることです。ビルドが始まる前に、より多くのスキャンを促すようにプロセスを調整する必要があるかもしれませんし、コードが消費されてレビューされる方法を変更する必要があるかもしれません。
重要なのは、ガバナンスがシステムのコントロールに影響を与える必要があるということです。ガバナンスは、アプリケーションのセキュリティに関する標準とルールの概要を説明しなければなりません。ガバナンスは、「当社の安全なコーディングガイドラインは何か」という質問に効果的に答えなければなりません。ガバナンスとは、ソフトウェアに関して意思決定を行い、期待されることを定義するための構造を形成する、ポリシー、標準、およびプロセスのフレームワークです。本質的には、ガバナンスは、セキュリティテストがなぜ、どのように全体的に行われているかを概説します。
まとめ
今回のブログでは、「Intensify」のテーマと「Educate」と「Govern」の能力に焦点を当てました。このシリーズの最終回では、「保証」のテーマと「測定と監査」の機能を見ていきます。
最後に、このシリーズの過去の記事を見逃してしまった方は、こちらからご覧いただけます。
HCL Sametime: エンドツーエンドの暗号化が必ずしも望み通りにならない理由:4つの重要な洞察
2020/8/22 - 読み終える時間: ~1 分
Why End-to-End Encryption Isn't Always What You Want: 4 Important Insights
エンドツーエンドの暗号化が必ずしも望み通りにならない理由:4つの重要な洞察
2020年8月21日
著者: HCL Sametime Team

重要なデータを保護するウェブチャットプラットフォームの価値ソフトウェアを選択している企業。 組織の安全なメッセージングと大きなセキュリティの評判を確保することは、目標だけでなく、要件でもあります。 暗号化は、そのセキュリティの基本的な柱です。
しかし、すべての暗号化は同じではありません。そして、その違いは重要です。 ここでは、暗号化の基本をいくつか取り上げ、エンドツーエンドの暗号化が企業にとって必ずしも最良の選択肢とは限らない理由を説明します。
セキュアなチャット ソフトウェアを購入する際に知っておくべき 4 つの洞察をご紹介します。
1. エンドツーエンド暗号化とは
エンドツーエンドは、WhatsApp や iMessage のようなメッセージングアプリによって使用が拡大しており、データ漏洩に悩むユーザーにクローズドなチャネルを提供している点で高く評価されています。メッセージは送信者側で暗号化され、受信者側の秘密鍵でロックが解除された場合にのみアクセスできます。
このようにして、通信全体が外部からの調査から遮断され、送信者と受信者の二者だけが利用できるようになります。
2. エンドツーエンドの暗号化を使用することの欠点
エンドツーエンドが個人にとって魅力的な理由は、外部からデータやメッセージにアクセスすることができないという点と同じですが、規制や監査が必要な企業にとっては機能的ではありません。完全に合法で安全なメッセージを保護するのと同じ要素は、違法で不正な素材も保護することになり、エンドツーエンド暗号化を使用して検出を逃れ、被害をもたらす悪意のある当事者にとっては、ある種の安全な空間を作り出してしまいます。
現実の世界では、エンドツーエンドのプライバシーは、そのプライバシーを悪用しようとする個人やグループを含め、すべての人に利益をもたらします。
3. 他の方法もあります
エンドツーエンドの認知度と人気が高まっているにもかかわらず、企業顧客が意識しておくべき重要な暗号化方法として、代替の暗号化方法があります。暗号化ソフトウェアがエンドツーエンドではないからといって、安全で保護されていないということにはなりません。実際、規制や法律上の要件がある業界では、エンドツーエンドではない暗号化に頼っているエンタープライズ企業が多くあります。
エンドツーエンドが唯一の暗号化方法であると考えるのはやめましょう。
4. 非エンドツーエンドが意味をなす場合
企業が使用するコミュニケーションツールには、毎日やりとりされるすべてのチャット、ファイル、ビデオを保護し、コンプライアンスや規制基準を満たすことができる監査可能な暗号化ソフトウェアが必要です。
エンドツーエンドの暗号化は、監査や簡単な調査ができないため、企業はネットワーク内で毒のあるやりとりや疑わしいやりとりがあったとしても、それを調査する手段がないという危険な状況に陥る可能性があります。
特に金融機関や政府機関は、監査や集中的なデータレビューによって強制される多数の規制基準を満たすことが期待されています。 安全なメッセージングと監査可能性の両方を提供する暗号化ソフトウェアを持つことで、企業は両方の利点を享受することができます。
これが、非エンドツーエンドの暗号化が多くの企業にとって意味のある理由です。
完全に安全でありながら、監査可能性を可能にするチャットと会議のプラットフォームとしての HCL Sametime にご注目ください。
HCL OneTest: ビジネス・プロセス・フローの自動化と検証
2020/8/22 - 読み終える時間: ~1 分
HCL OneTest UIは、HTML 5、Java、Windows、.NET、Visual Basic、SAP、Silverlight、Eclipse、Siebel、Flex、Ajax、Dojo、GEF、PowerBuilderアプリケーションを含む、HTMLをテストするオブジェクト指向の自動機能テストツールです。また、ビジネス・プロセス・フローの検証にも対応できます。そのことについて書かれた英語版ブログの記事 Automating and Validating Business Process Flows の翻訳版です。
ビジネス・プロセス・フローの自動化と検証
2020年8月21日
著者: Nabeel Jaitapker / Product Marketing Lead, HCL Software

ビジネスプロセスの検証は、数回クリックするだけで作成される複雑なテストアサーションを可能にする、シンプルでありながら強力なスクリプトツールを介して行う必要があります。
さらに、ユーザーが開発プロセスに自動テストを組み込み、納品物の品質を向上させることができるように、DevOps パイプライン(Jenkins、UrbanCodeなど)への統合が必要です。
HCL OneTest UI は、3270 インターフェイスを持つメインフレーム端末から、.NET や Java ベースのシッククライアントアプリケーションを介して、テスト担当者が自動化を行うことを可能にします。
さらに、最新のトップブラウザ、SAP や Oracle などの ERP システム、Angular、React、Vue.js などの最新フレームワークで構築された HTML5 ベースのレスポンシブ Web アプリケーションにも対応しています。
HCL OneTest UIの詳細については、こちらをご覧ください。
HCL Accelerate: あなたがお使いのアイテム追跡ツールだけでは不十分な理由
2020/8/22 - 読み終える時間: 2 分
HCL Accelerate はボトルネックを特定するツールですが、その前提として、あらゆる工程を追跡する機能を持っています。その特長について記した記事 Your item tracking tools aren't enough. Here's why の翻訳版です。
あなたがお使いのアイテム追跡ツールだけでは不十分な理由
2020年8月21日
著者: Bryant Schuck / Product Manager for HCL Software DevOps

スクラムボードのようなアイテムトラッキングツールについてどう思うか、開発者やチームリーダーに聞いてみると、否定的な答えが返ってくるでしょう。ほとんどの開発チームが使用しているトラッキングツールは、必要悪とみなされたり、貴重な仕事を成し遂げるための障害物とみなされたりします。スクラムボードは常に時代遅れで、開発者だけが知っている微妙な情報があり、ボード上では簡単には伝えられません。スクラムボードは手作業であるため、いくら状態やカラムを作成しても、情報には常にわずかな矛盾があります。
Jira のような作業項目追跡ツールは、プロジェクトの初期計画のために最低限の要件を収集し、チームの作業項目のバックログを構築するという目的には最適です。これらのトラッキングツールがバラバラになり始めるのは、作業が最初の計画段階から進行中の段階に移ったときです。この時点で、多くのチームはスクラムボードやカンバンボードを使用して、作業アイテムがパイプラインのどこにあるかのステータスを追跡しています。これでは、たくさんの列がある乱雑なボードになってしまい、開発者は自分のワークアイテムカードが正しい位置にあるかどうかを確認するために、多くの手作業や退屈な作業をしなければならなくなる可能性があります。その結果、ボードを整理したり、カードが正しい位置にあるかどうかを確認したりするために、無駄な時間を使ってステータスミーティングを行うことになります。ボードが常に正確でないと、本来の価値を失い、管理者は計画を立てるためにボードを頼りにすることができなくなります。そうなると、管理者は開発者を困らせ、状況の更新を求めて開発者に直接連絡を取るようになります。
Standups は、開発者がスプリントを成功裏に完了させるために何をすべきかを知るための方法ではなく、管理者のためのステータスミーティングになってしまっているのです。ミーティングは、ステータスレポートの更新ではなく、価値を高めるためのものでなければなりません。では、なぜステータス ミーティングで時間を無駄にしているのでしょうか?それは、作業を追跡するために使用しているツールが、実際にはより多くの作業を生み出しているからです。
複数のツールにまたがって DevOps データの集計を開始すると、ステータスミーティングの必要性がなくなります。これがまさに、バリューストリーム管理ツールである HCL Accelerate が行うものです。 開発者から手動で入力することなく、チーム全体のすべての作業項目の誰、何、いつ、どこにいるかを明確に示す、常に最新のライブバリューストリームにすべてのデータをまとめます。
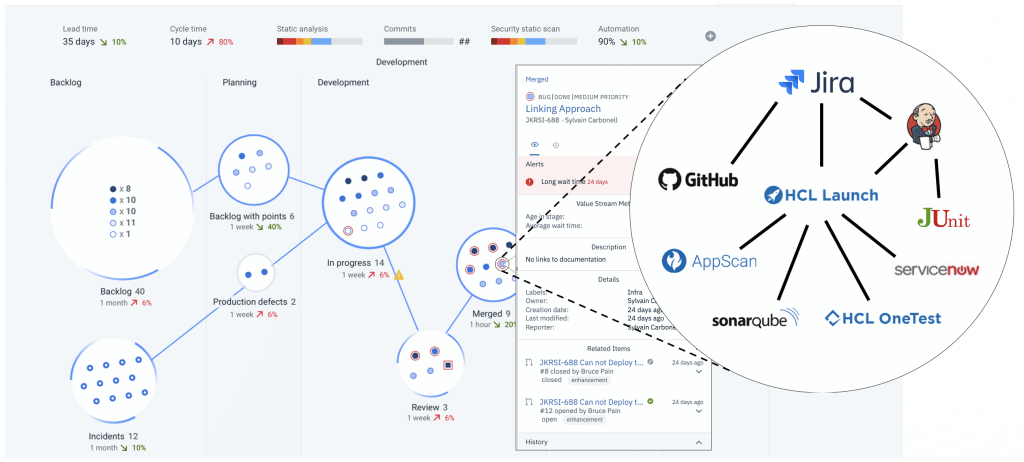
HCL Accelerate は、すでに使用しているすべてのツールからデータを集約するので、手動でのステータス更新に別れを告げることができます。
ステータスチェックの必要性がなくなると、最初の大きな成果は、立ち見のミーティングの時間を取り戻すことです。価値を生み出す本当の仕事にすぐに集中し、開発者が仕事を完了させるために直面している障害に対処し始めることができます。スタンドアップ ミーティングでの会話は、「これは正しいデータか」から「どうすればチームの進歩に貢献できるか」へと変化します。さらに良いことに、「カードを作るのを忘れてしまった」という話を二度と聞く必要がありません。 DevOps パイプライン内のすべてのツールからデータが集約されているので、Jiraの問題、ServiceNowのチケット、またはGitHubの不正なプルリクエストから来る予定外の作業によるサプライズを心配する必要はありません。
HCL Accelerate は手動入力に頼るのではなく自動化されているため、正確なステージ完了データを得ることができ、パフォーマンスの高いチームを特定したり、ボトルネックをクリアしたりすることができます。開発者にとっては、これは管理作業を減らし、パイプラインに直接影響を与えるタスクでのマネージャーのサポートを増やすことを意味します。管理者にとっては、信頼できるデータ、可視性の向上、より正確な計画の策定を意味します。
しかし、開発者は新しいツールへの切り替えを嫌がり、使用しているアイテムトラッキングソフトウェアの周りにはすでにプロセスがあります。私たちはそれを理解しています。しかし、HCL Accelerate は、リッピング&リプレース型のソフトウェアではありません。Jira、GitHub、Jenkinsなどの使い慣れたツールを使い続けることができ、HCL Accelerate はデータを掬い上げて、価値の流れの真実の単一ソースを提供します。プロジェクトの全体像をまとめるためにツールからツールに切り替える時代は終わりました。HCL Accelerate は、ツール間、チーム間、職務間のギャップを埋めます。
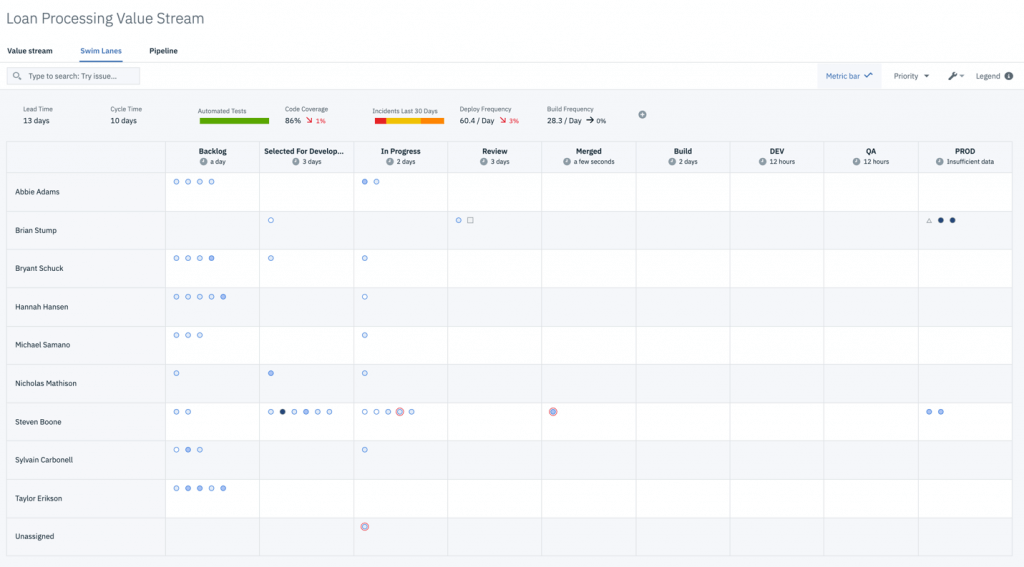
HCL Accelerateの「スイムレーン」ビューでは、作業項目がどこにあるのか、どのチームメンバーにサポートが必要なのかを明確に把握することができます。
すべてのソフトウェア企業は、競争の一歩先を行き、より多くの価値を生み出す方法を探しています。しかし、パイプラインがつながっていなければ、データや手動プロセスのギャップを埋めようとすることで、常に不利な状況に陥ってしまいます。HCL Accelerate は、ワークアイテムのトラッキングと KPI 測定を自動化し、チームがこれまで以上に機能するようにします。競争上の優位性はどうでしょうか?
自動化されていない限り、誰もデータを信じません。開発者と管理者の両方にとって、HCL Accelerate は、より良い意思決定のための正確でライブなデータにより、仕事を楽にします。無料の HCL Accelerate Community Edition で今すぐ始めましょう。
HCL Accelerate: GitHub と Jira と組み合わせた HCL Accelerate Value Stream Management
2020/8/22 - 読み終える時間: 9 分
今回は Jira と GitHub の活動を統合して見える化する内容 HCL Accelerate VSM with GitHub and Jira の翻訳版です。
GitHub と Jira と組み合わせた HCL Accelerate Value Stream Management
2020年8月20日
著者: Daniel Trowbridge / Technical Lead
このチュートリアルでは、HCL Accelerate で GitHub 統合を作成する方法を説明します。これは、Jira、GitHub 、Jenkins を使用して HCL Accelerateのバリューストリームを設定し、使用するチュートリアルシリーズの第2部です。一部のバリューストリームのステップは、Jiraチュートリアルの完了を前提としています。Jiraチュートリアルを完了していない場合は、ここで完了できます。
1. GitHub リポジトリを設定する
GitHub の要件は以下のとおりです。
- GitHub リポジトリへのアクセス (このワークブックでは公開リポジトリを想定しています)
- GitHub API トークン
- プルリクエスト (PR) を作成する機能。
このワークブックは、公開 GitHub アカウントと公開リポジトリを前提としています。公開 GitHub アカウントを持っていない場合は、公開リポジトリと同様に作成する必要があります。リポジトリの内容は重要ではありませんが、PRが必要で、PR名には、フォローするJira課題の課題IDが含まれていなければなりません(ここでの例は"JKET-1")。
2. GitHub インテグレーションを作成する
注: GitHub プラグインの設定はバージョン 1.0.31 から変更されました。バージョン1.0.31 以降では、URL フィールドは必要ありませんが、下記のステップ 9 のようにユーザーアクセスキーが必要になります。
- HCL Accelerateのプラグインページ(設定>統合>プラグイン)から統合を追加できます。
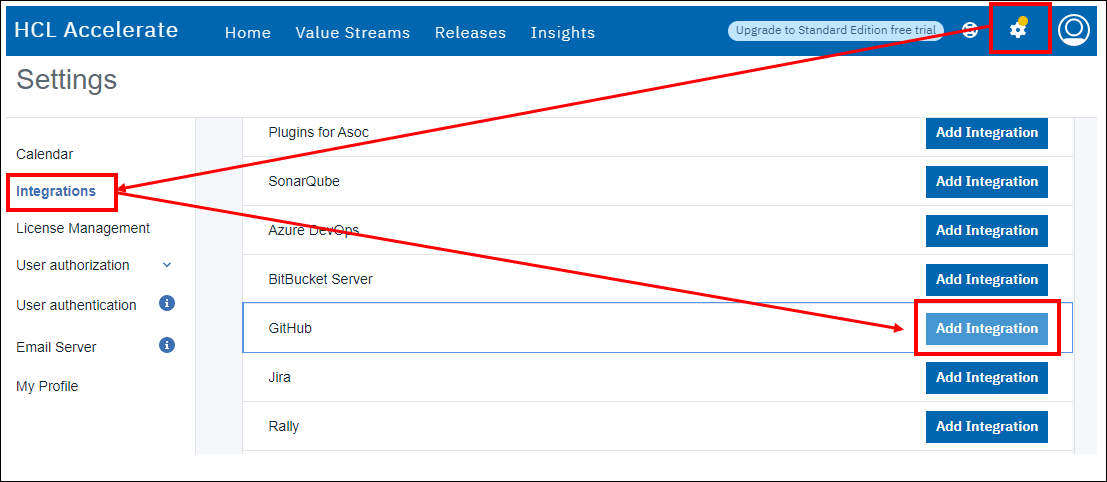
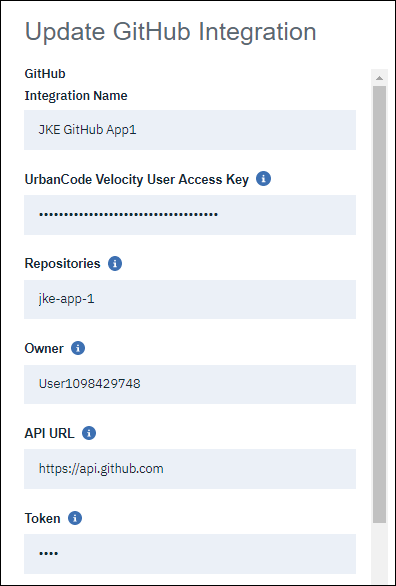
- このワークブックの統合名は「JKE GitHub App1」としてください。

- GitHub のURLはリポジトリへのURLにしてください (プラグインのバージョン1.0.31以降では必要ありません)
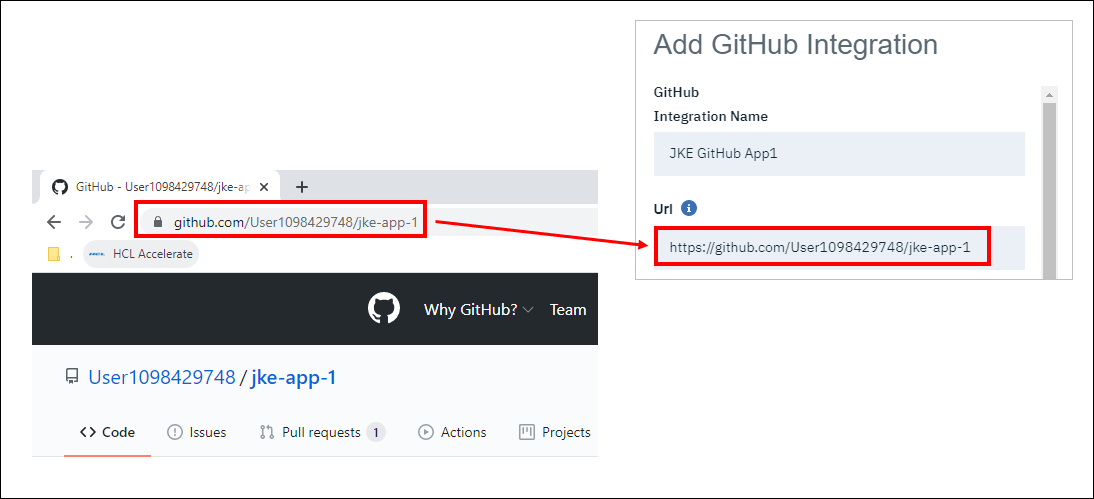
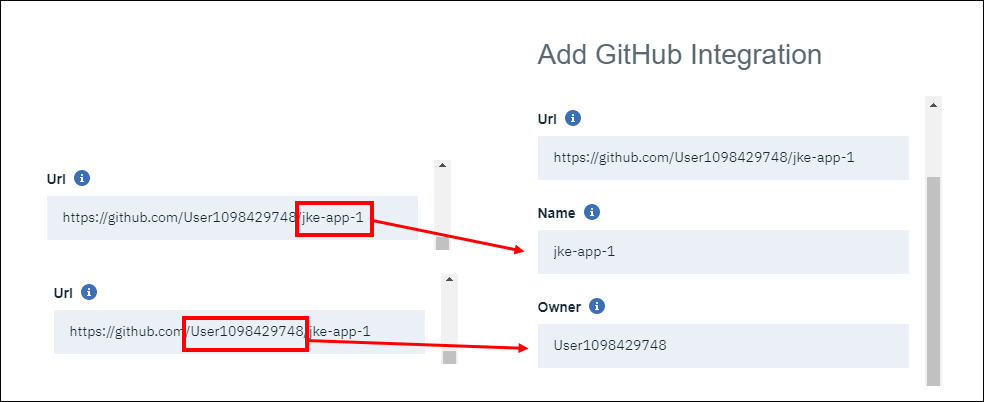
- GitHub リポジトリ URL から「名前」(リポジトリ名)および「所有者」(リポジトリアカウント)フィールドを取得できます。
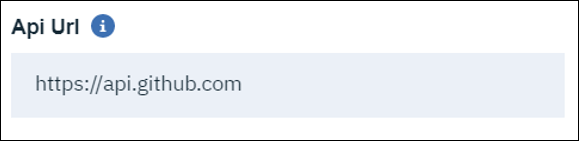
- API URLは GitHub のインスタンスに依存します。このワークブックでは、"https://api.github.com" を使用する GitHub のパブリックインスタンスを想定しています。
- リポジトリにアクセスできるアカウント用の GitHub パーソナルアクセストークンを作成し、そのトークンをコピーして統合フォームに貼り付けます。GitHub の公開トークンは https://github.com/settings/tokens で作成できます。トークンを作成する際に、「スコープ/権限」のチェックボックスを選択する必要はありません。

- 追加」ボタンをクリックして統合を作成します。統合」ビューに移動して、統合が作成され、「オンライン」になっていることを確認します。ドロップダウンを展開して、統合の詳細を確認できます。(以下に示す Jira 統合は、別の演習の一部として作成されたことに注意してください)
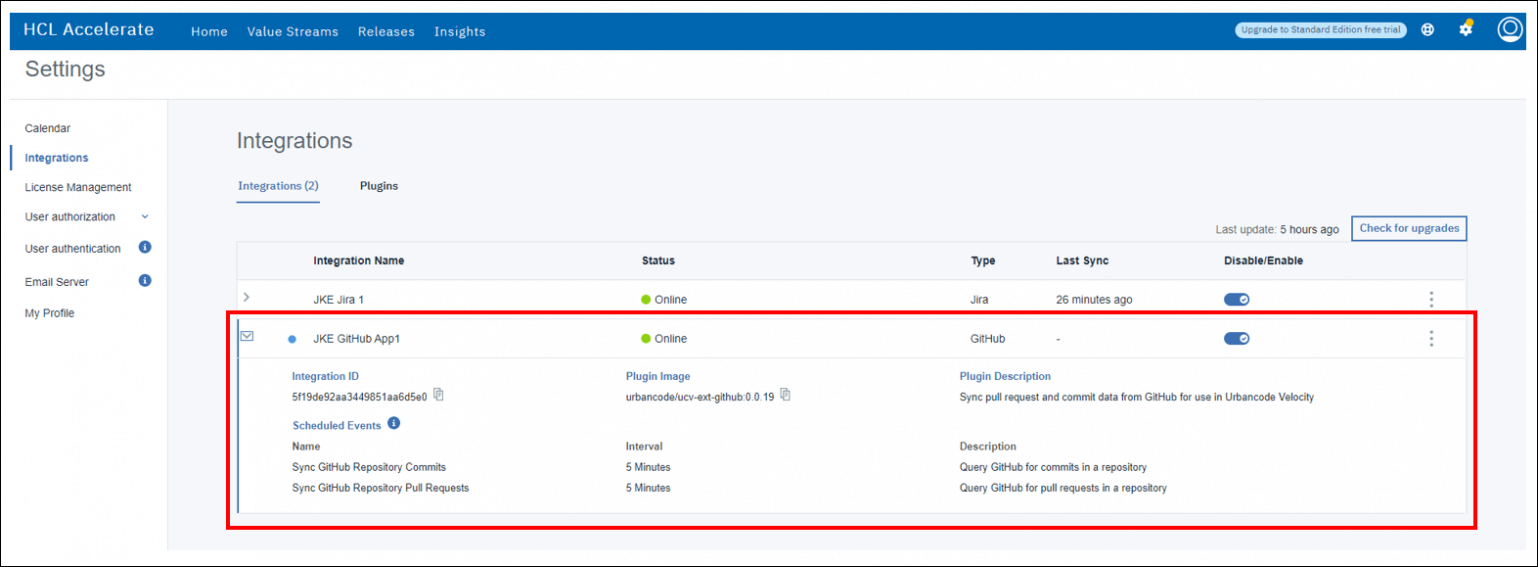
- 統合名の横にある青い点は、アップグレードが可能であることを示しています。この時点でプラグインをアップグレードしておくと良いでしょう。三角点(カボブ)メニューの下にある「アップグレード」をクリックします。プラグインイメージが最新バージョン(1.0.36以降)に更新されるはずです。

- ユーザーアクセスキー( GitHub プラグインのバージョン1.0.31以降。
-
GitHub プラグインのバージョン1.0.31以降では、HCL Accelerateユーザーアクセスキーが必要です。URLフィールドも削除されました。1.0.31以前のバージョンからのアップデートでは、ユーザー・アクセス・キーとの統合を編集する必要があります。
-
アクセスキーを作成するには、「設定」→「マイプロフィール」で「作成」をクリックします。アクセスキーを作成するには、「設定」→「マイプロファイル」→「作成」をクリックします。アクセスキーの名前は、それを使用する統合に合わせて、「JKE GitHub App1」のような名前にするのが良いでしょう。この時点でキーをコピーしておくと後でコピーできなくなるので、必ずコピーしておきましょう。
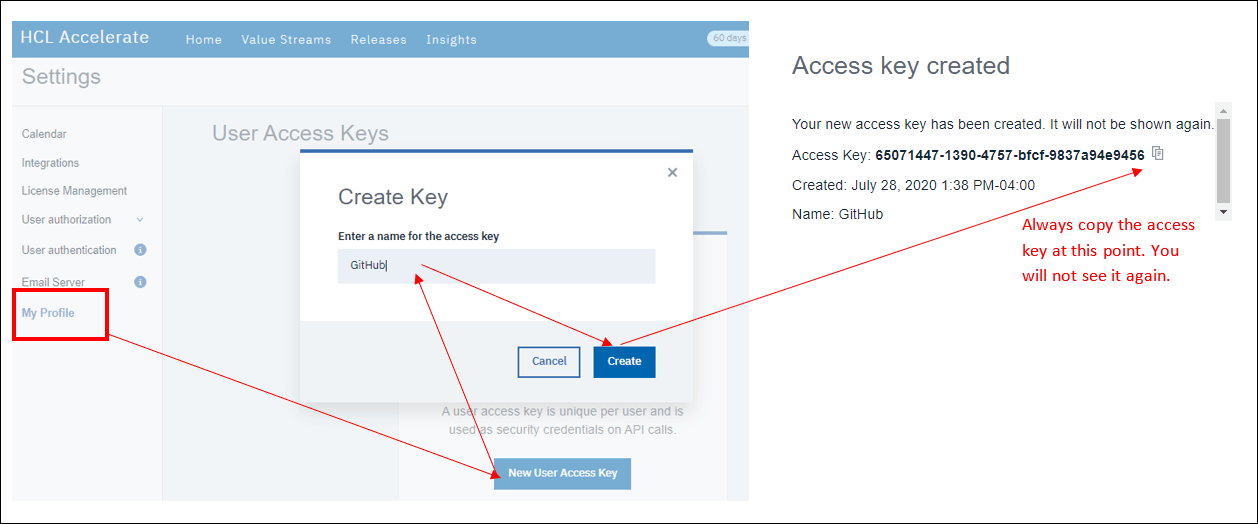
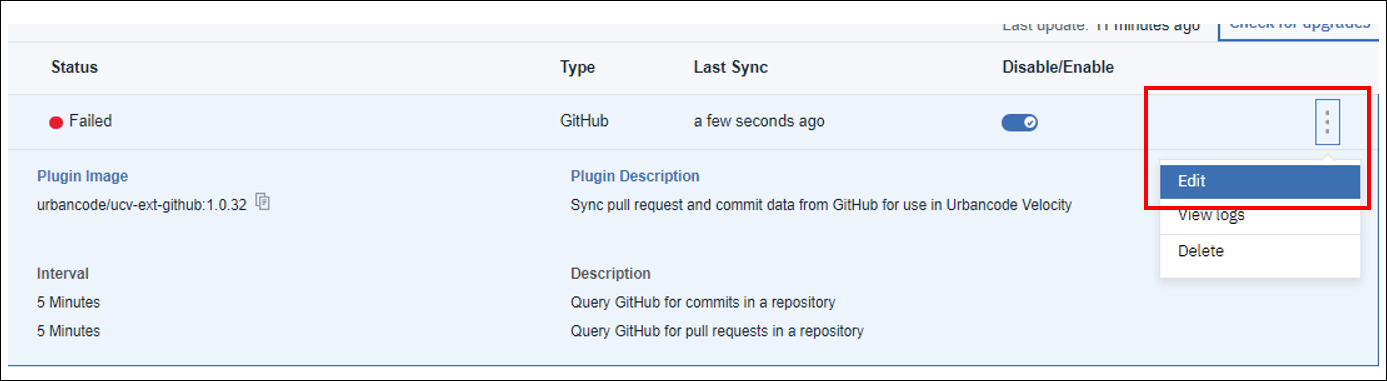
- キーを作成したら、統合ページに戻ります。GitHub 統合の kabob メニューから「編集」をクリックします。フォームにユーザーアクセスキーを入力します。
3. GitHub インテグレーションをバリューストリームに追加する
vsm.json ファイルを使って、GitHub 統合と linkRule を値のストリームに追加します。ファイルをダウンロードして、以下のセクションを追加して修正し、再度ファイルをアップロードして変更を適用します。PR が開いているので、作業項目 (ドット) は"In Progress" ステージに移動するはずです。PR またはコミットが作業項目に正しくリンクされていない場合、四角(PR)または三角(コミット)として表示されますが、ドットはリンクされたすべての PR とコミットを含む実際の作業項目を表します。1つの作業項目に複数のPRをリンクできます。PR ブランチへのコミットは、ワークアイテムを更新します。
注: この時点から、いくつかのステップでは、Jira チュートリアルを使用して VSM を事前に完了していることを前提としています。チュートリアルをまだ終えていない場合は、今すぐ完了させるか、Jira との統合を行わずに先に進んでください。GitHub は統合されて PR やコミットを表示できます。しかし、イシュートラッカーの統合とそれに対応するリンクルールがなければ、作業項目のリンクはできません。以下のように vsm.json ファイルを編集して GitHub との連携を含めることに加えて、ステージクエリを編集する必要があります。
"query":"pr.status=open".
- 作業用の vsm.json ファイルを値ストリームからダウンロードします。
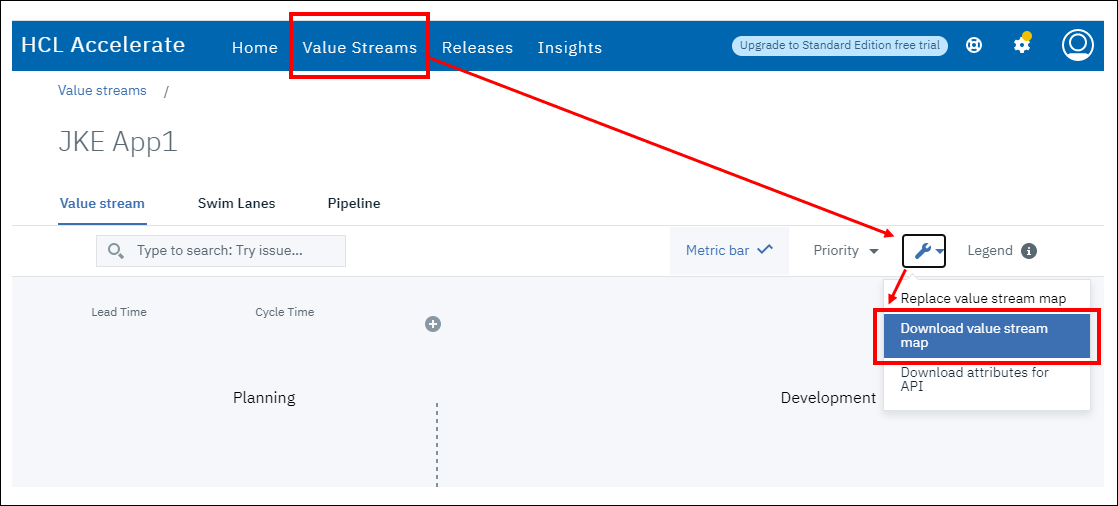
- GitHub 統合を .json コンテンツに追加します。
別のチュートリアルでJiraの統合を追加するために使用したjsonと同様に、もう一つのjsonオブジェクトを統合配列に追加する必要があります。ここでの名前は、先ほど作成した GitHub 統合の名前と一致させなければなりません。今のところ必要なのは、GitHub オブジェクトをシングルネームプロパティで追加するだけです。vsm.json に Jira のような他の統合が含まれている場合は、無視しても構いません。
"integrations". [
{
* 名前":"JKE GitHub App1"
}
//その他の統合...
],- vsm.json の設定に GitHub -Jira の linkRule を追加します。
空のリンクルールの配列を置き換える...
"linkRules". [],
に新しいリンクルールオブジェクトを含む配列を指定します。この linkRule は、pr.name の中の jira.id を認識する正規表現パターンに基づいて GitHub の PR と Jira の課題をリンクします。
"linkRules". [
{
* fromIntegrationName"。"JKE GitHub App1".
* toIntegrationName"。"JKE Jira 1".
*"fromField"."pr.name":"pr.name
*"toField"."issue.id":"issue.id
*"パターン"です。"([A-Z]+-[0-9]+)"
}
],- vsm.jsonファイルを保存してアップロードします。
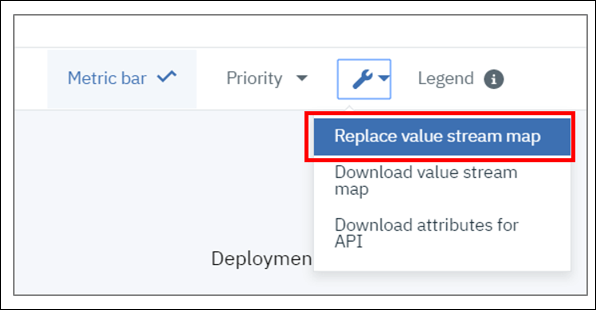
四角が見えますか?
GitHub の活動にもよりますが、"Merged" のようなステージにいくつかの四角が表示されていることに気づくかもしれません。これは、Jira カードにリンクされていない以前のコミットを表しています。私たちは新しい PR を作成して Jira カードにリンクさせることに焦点を当てているので、このような四角が表示されても無視して構いません。
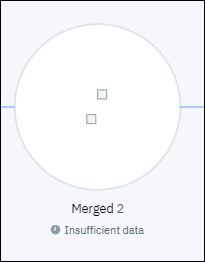
4. Jiraと GitHub を使ったステージ変更
さて、GitHub をインテグレーションとして設定したところで、次はバリューストリームの中で GitHub を実際に使ってみましょう。GitHub はスタンドアロンの統合として使うこともできますし、さまざまな統合と一緒に使うこともできます。ここでは、Jira チュートリアルの VSM を使用していることに注意してください。
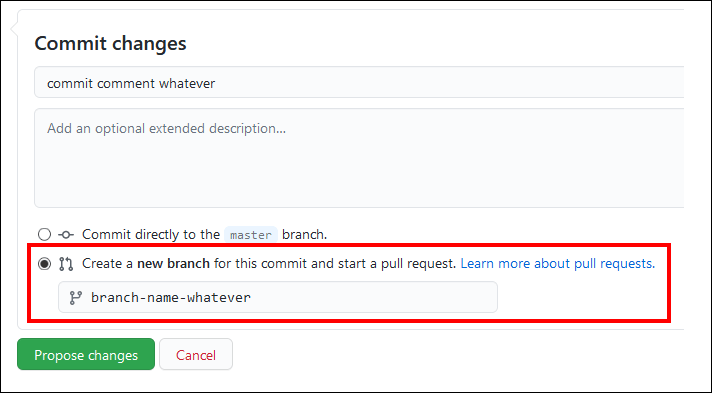
4.1 ドットを「進行中 (In Progress)」に移動する(PRを作成する)
ドットを「進行中」の段階に移動させるには、GitHub でプルリクエスト(PR)を作成する必要があります。
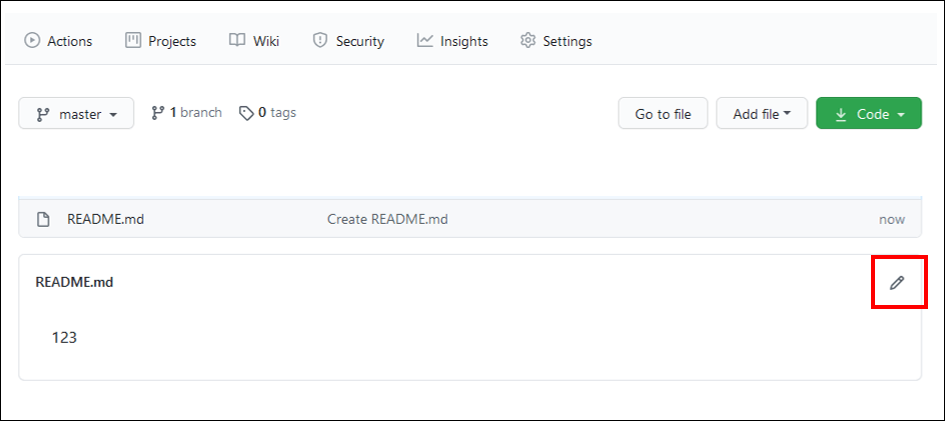
-
リポジトリ内の任意のファイルを編集します。この例では、ファイルの右上にある鉛筆のアイコンをクリックして編集できる、README ファイルを編集しています。
-
ファイルに変更を加えます。これらの変更は、以前に作成した Jira カードに対応するものと考えてください。これは、そのカードのコード変更を表しています。
-
変更を別のブランチにコミットします。コミットメッセージとブランチ名は好きなように設定できます。
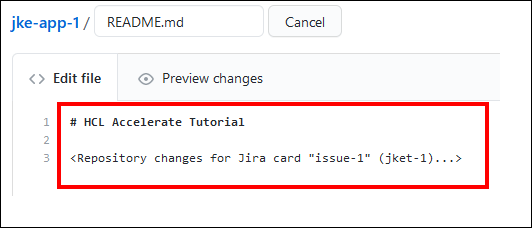
-
プルリクエストを作成するように促されたら、プルリクエスト名に Jira カードの ID/コード (例:"JKET-1") を入力し、"Create pull request" をクリックします。
- プルリクエストがオープンで、JiraカードのIDが含まれていることを確認します。
- HCL Accelerateが検出して更新されるのを待った後、「進行中」の段階でドットが表示されるはずです。
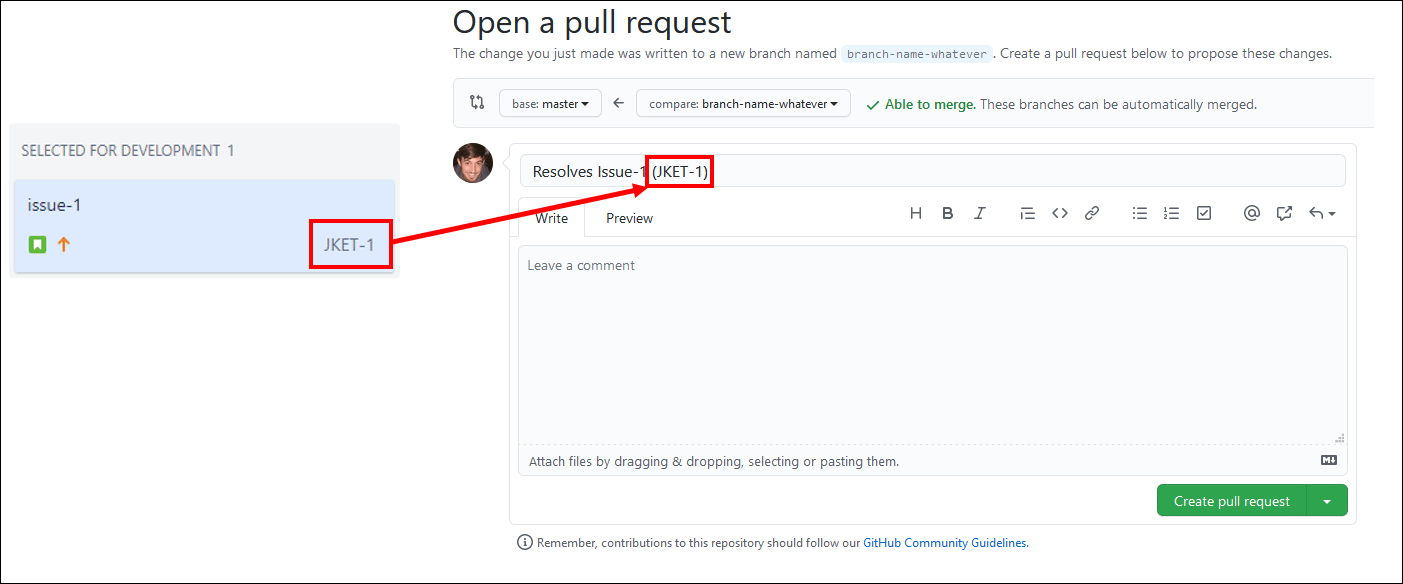
4.2 ドットを「レビュー中 "In Review"」に移動する
- Jiraカードを"In Review"に更新してください。
- HCL Accelerateが更新されるのを待ちます。ドットが "In Progress" から "In Review" に移動するはずです。
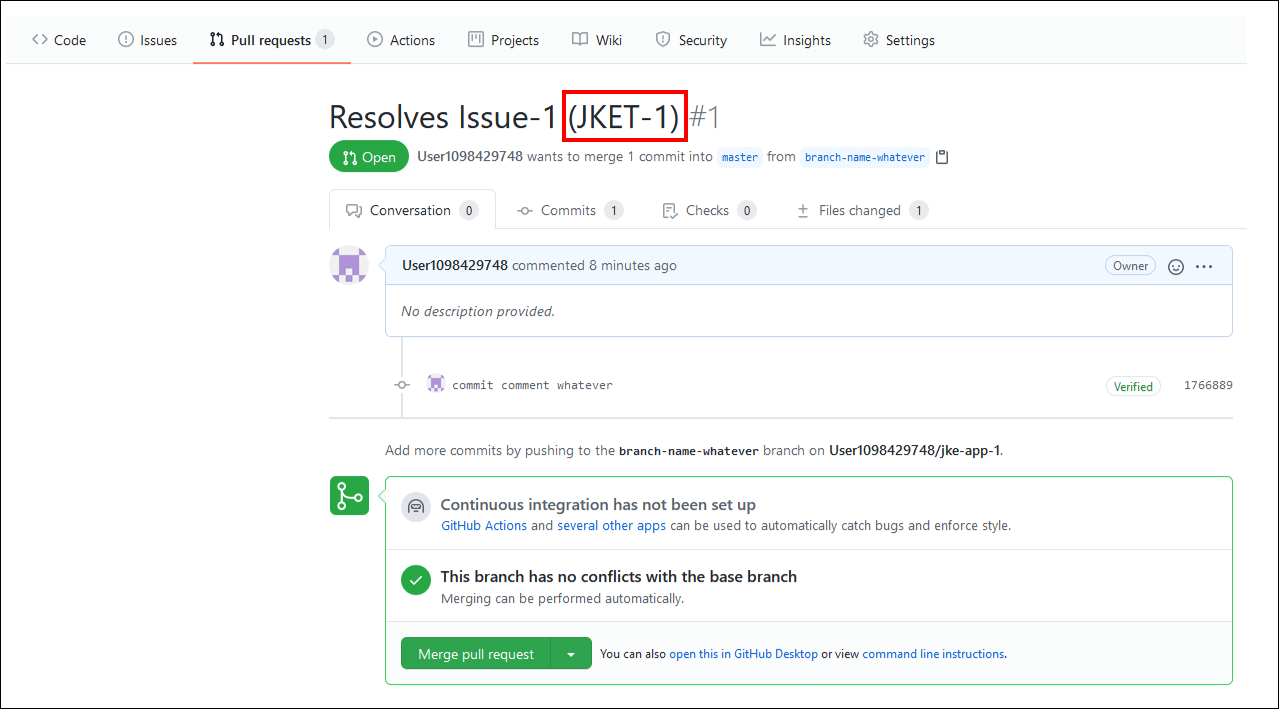
4.3 ドットを「マージ済み (Merged)」に移動する
- 先に進み、GitHub で PR をマージします。
- HCL Accelerateがアップデートされるのを待ちます。ドットが"In Review"から"Merged"に移動するはずです。
次のステップへ。開発からサーバー構築、そしてその先へ
Wow! Jiraと GitHub の両方の活動が、HCL Accelerateで一つの真実のソースになるのを目の当たりにしています。次のステップは、ビルドとデプロイメントを統合して、本番まで作業項目を追跡することです。そのためには、Jenkins との統合を作成する必要があります。
HCL Unica の Docker 対応
2020/8/20 - 読み終える時間: 4 分
HCL Software では仮想コンテナに積極的に対応しています。HCL Unica も V12 で対応しました。それについての英語版ブログの記事 Unica is Dockerized の翻訳版です。
HCL Unica の Docker 対応
2020年8月19日
著者: Siddharth Deshpande / Architect for Unica Cloud-Native Solution

Unica V12 には素晴らしいものが搭載されています 私たちは先日、「The 12 Things We Love About Unica V12.0」というシリーズを発表しました。このシリーズでは、集中的なオファー管理の場から、デプロイメントのためのクラウドネイティブ化の機能まで、展開されている側面に焦点を当てています。Unica がいかに簡単にインストールでき、オンデマンドで拡張でき、アップグレードも早く、これだけの関心を集めているかを実証しています。
"#UNICAisDockerized"
Dockerは現在、最も人気のあるコンテナ化技術の一つであり、業界の話題となっています。HCLでは、より高いユーザビリティ、柔軟性、高いレベルの安定性を求めるお客様のニーズを理解しています。私たちは、最新の技術でこれらすべてを提供できるように努力しています。 Docker が Kubernetes や Helm のようなツールの利用可能性とともに普及するにつれ、Docker は必要な専門知識を持ったIT専門家にとっての恩恵となっています。これにはビルド済みの Docker イメージだけでなく、Kubernetes や Helm のオーケストレーション機能を活用することも含まれています。HCL Softwareでは、Unica Suiteのフルバージョンを含む、最近買収した製品のいずれも、一日に何度も繰り返されることはありません。v12.1のリリースにより、Unica はすべての製品を Docker 化し、Dockerイメージを Kubernetes 上で Helm のチャートを使ってデプロイできるようになりました。Docker 化された Unica 製品は、簡単なインストールからクラウド対応まで多くのメリットがあります。
Docker は CMO、CTO、マーケティングリーダーシップ、ユーザーにとってどのような問題を解決するのか?
リーダーシップ(CMO、CTO、その他の C レベル)にとって最も重要な問題は、ソフトウェアの流通性と信頼性です。ソフトウェアのバージョンの停滞は、マーテック業界で発生している既知の問題です。
これは、どのような初期バージョンの Martech ソフトウェアがインストールされていても、ほとんどアップグレードされないという状況です。Journey のゴールベースマーケティングや、ソフトウェアの新機能やアップデートに伴うドラッグ&ドロップ機能など、素晴らしい新機能を体験するための課題に直面しています。これらの機能をすべてUnicaのバージョンでどのようにアップデートできるかについて詳しく知りたい場合は、バージョン 12 の 12 のことや、Dockerを使用することで、これらの機能がシームレスにUnicaのバージョンに統合される方法をお読みください。CMOやその他のUnicaユーザーは、簡単かつ頻繁に修正や機能アップデートを行い、安価にソフトウェアをアップグレードして、競争力のある機能と最先端の機能を維持したいと考えています。また、コストのかかる複雑なアップグレードプロジェクトや、2020年版Unicaの新機能を最新の状態で利用できるシステムなど、長いサイクルを経ることなく、チームの生産性を向上させたいと考えていました。
堅牢性 - オンプレミスとクラウドファースト
当初、Unica はオンプレミスのソリューションとしか見られておらず、クラウド戦略以外でのワンオフサポートが必要でした。しかし、トランスフォーメーションの推進時代を迎え、クラウドファーストの戦略マインドを持つUnicaは、DockerizationとCICDにより、あらゆるインフラ戦略に対応したクラウド対応が可能となりました。Unicaは現在、業界で最も柔軟性と拡張性に優れた最新のMartechソリューション(v12.1)を提供しています。
Unica on Cloud の戦略的・技術的な詳細については、いつでもお問い合わせください。
マーケティングリーダーは、通貨性、信頼性、オープンな統合性、スピードを求めています。私たちがUnicaマーケティングリーダーから聞いた主なフィードバックは、通貨と統合機能に関するものでした。彼らが求めていたのは、修正の迅速なターンアラウンド、よりオープンな統合、そしてよりクラウドフレンドリーなソリューションでした。Docker 化されたリリースにより、V12は最新の状態を維持し、信頼性を継続的に向上させ、V12の20%の速度向上を超える機能を提供し、よりクラウドに適したソリューションを提供します。20%の速度向上を実現し、よりクラウド、データベース、APIフレンドリーなソリューションを提供することで、よりシンプルで低コストの統合を実現します。
Unica ユーザーは常により多くの機能や機能を望んでおり、Docker 化された CI/CD のアップグレードにより、フォーラムやイベントでの製品フィードバックが想像以上に早く現実のものとなることをユーザーが実感できるようになりました。機能、機能、修正へのアップグレードはすべて、ユーザーのテストサイクルを大幅に短縮しながら、非常に迅速に提供することができます。V12以降のリリースでは、Unicaスイートにさらに多くの機能を追加しているため、柔軟性が向上し、機能が大幅に向上しています。
v12.1 では、UnicaはDocker 化をサポートし、プレミスにとらわれないクラウド対応のソリューションを提供するエンタープライズクラスのCXプラットフォームとなっています。
HCL Unica Docker イメージ
Unica Marketing Suite は完全に Docker 化されています。Unica 製品にはそれぞれ別の Docker イメージ が用意されています。
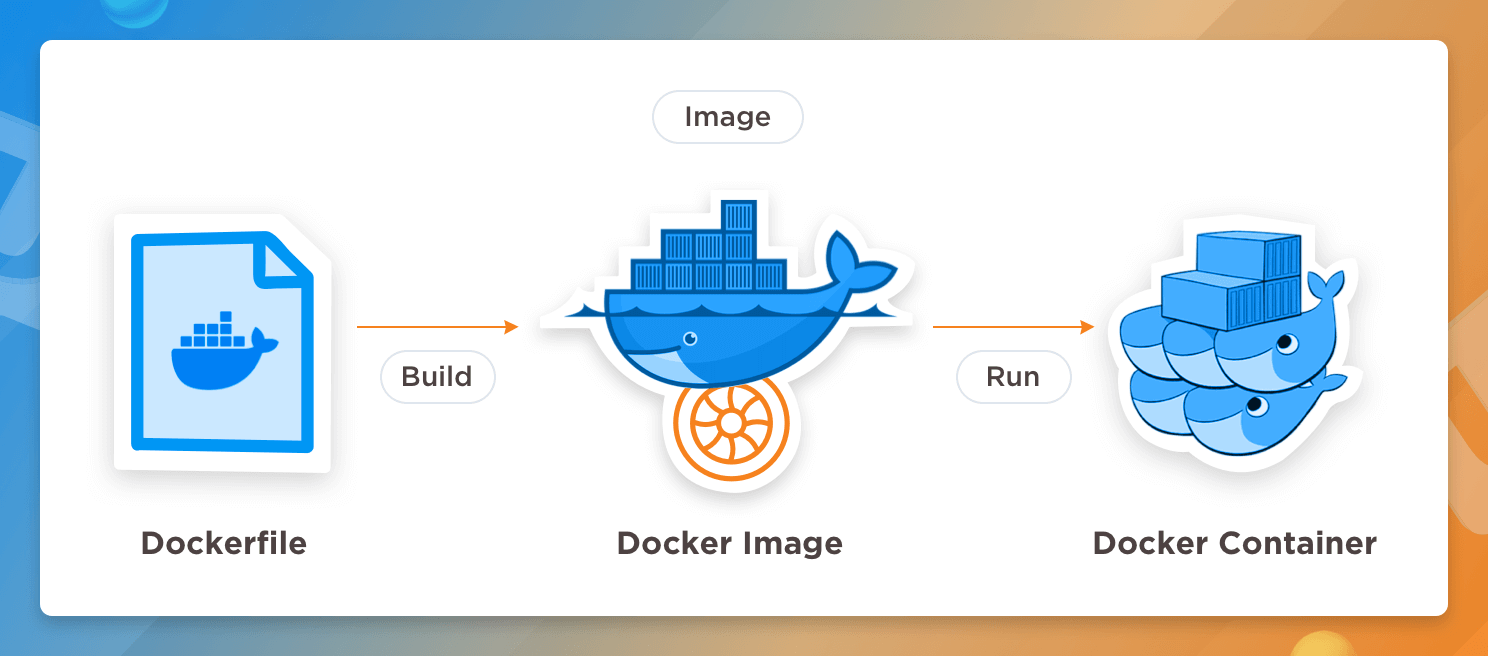
以下に v12.1 Unica Docker イメージのリストを示します (これらは HCL Software License Management Portal で利用可能です)。
- Platform
- Campaign (https://help.hcltechsw.com/unica/uc/campaign.html)
- Plan
- Interact
- Centralized Offer
- Insights
- Content Integration
- Journey
- Director
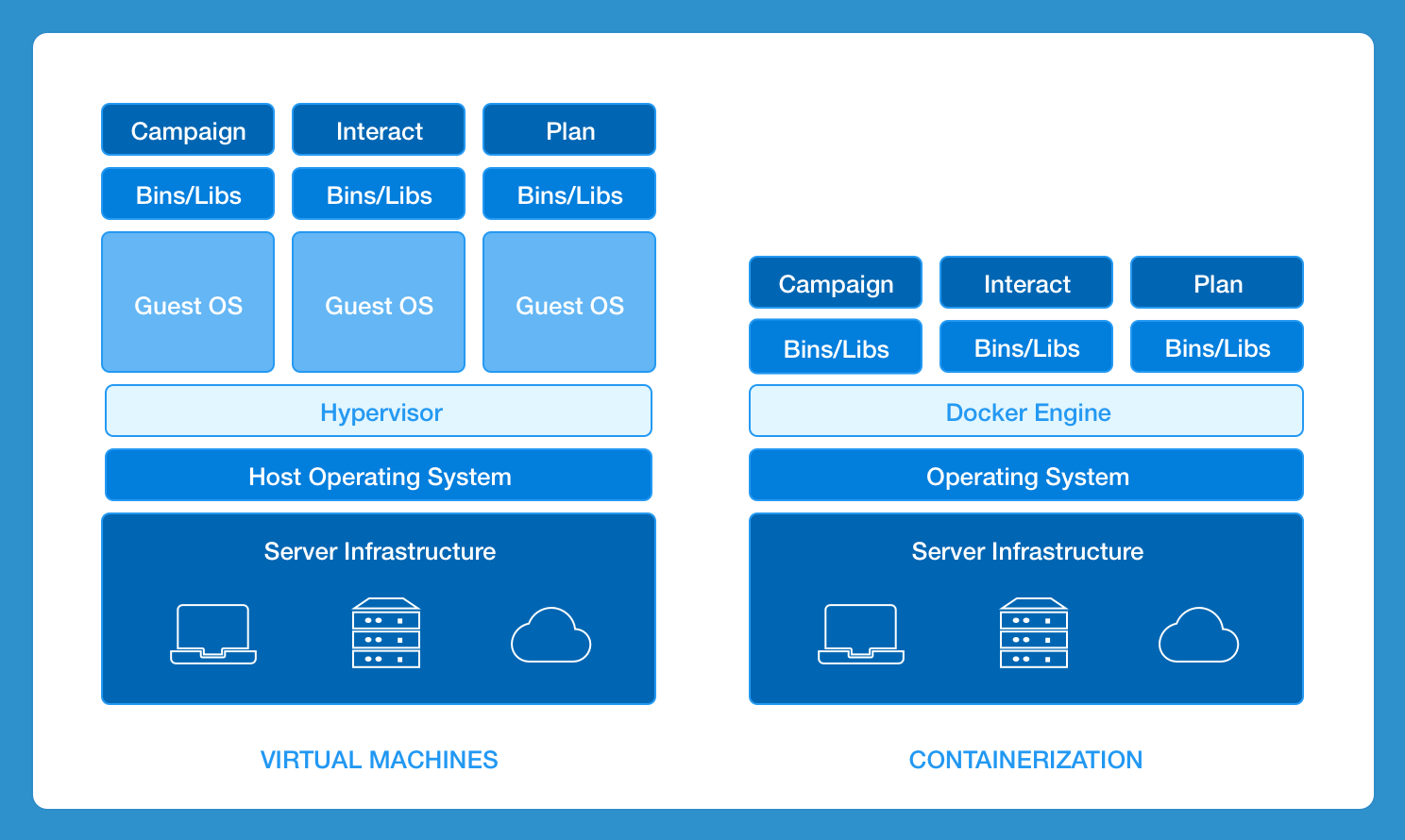
仮想マシンと連携
Docker 化は、CI-CD という概念にUnicaスイートを開放します。CIを導入することで、短縮された望ましいリリースサイクルを実現することができます。
Unica Docker イメージでサポートされているテクノロジースタックは
Tomcat、JBoss EAP、Weblogic などのアプリケーションサーバーがサポートされています。Tomcatはイメージ内に組み込まれています。これにより、アプリケーションのインコンテナJVMプロセスが可能になります。JBoss EAPとWeblogicは外付けのアプリサーバーです。Oracle、DB2、MariaDBはDockerソリューションでシステムデータベースとしてサポートされています。UnicaのDockerイメージはcentosベースで、Linux OSはHelm Chartsを使用した Docker デプロイに対応しています。
Dockerイメージのデプロイ
Unica Helm Charts を使用して、完全に自動化された構成主導型のUnicaのインストールとデプロイが可能になりました。Unica Docker イメージ を使用することで、オンプレミスからDocker版へのアップグレードもサポートされています。Unica Docker Containersは、このアップグレードを完全に管理します。システムをスケーリングし、簡単なアップグレードを管理するための簡単なパスを提供するために、Docker 化は多くのクライアントと私たちを助けてきましたが、これ以上嬉しいことはありませんでした。
アンシアがDockerと連携する革新的な方法についてもっと知りたい方は、クラウドネイティブデプロイメントと 12-things-no12-dockerization について実施したウェビナーをご覧ください。

DevOps: Design Sprint? 流行っていますが、あなたのチームには効果があるでしょうか?
2020/8/19 - 読み終える時間: 3 分
Design Sprint? It's all the rage, but will it work for your team?
Design Sprint? 流行っていますが、あなたのチームには効果があるでしょうか?
2020年8月19日
著者: Ben Vance / UI Designer for HCL Software DevOps

バックストーリー(生い立ち、これまでのこと)。どのようにしてここまで来たのか?
率直に言います。
COVID-19 パンデミックとワーク・フロム・ホームの「ニューノーマル」の始まりに際し、私たちはかなり大きな設計プロセスの失敗をしました。設計に1ヶ月もかからないはずの新機能が、3ヶ月近くもかかってしまいました...最終設計はかなり最初の設計に近いものになってしまいました。全員がオフィスにいたとしても、非効率なことは起きていたでしょうが、リモートであることが問題をさらに悪化させ、そのうちのいくつかの問題が発生しました。
- プロジェクトの開始時に明確な要件がなかったこと
- 最初のミーティングにキーパーソンがいないこと
- プロセスを通して新しい人を連れてくる
- 会議の間隔が長い
では、それぞれの問題を詳しく見ていきましょう
- 私たちが始めたとき、「成功」とは何を意味するのか、明確な考えがありませんでした。さらに悪いことに、誰もが「成功」の意味するところが違っていました。だからデザイナーとして、私たちは動き続ける的中率の矢を暗闇の中で撃っていました。私たちは、ある用語が実際に何を意味するのかを定義し、再定義することに何時間も費やしました。
- 私たちは、ビジネスの "上の方 "にいる数人の主要なステークホルダーからプロセスを始めました。私たちは、彼らの考えと賛同を得ることで、デザイナーがまとめたソリューションを実装するために開発者を引き入れることができると考えました。問題は、開発者がそれぞれの考えを持っていたこと、さらに重要なことは、以前に設計された製品からの洞察を含めて、製品がどのように機能するべきかについての異なる洞察を持っていたことでした。
- 開発者を引っ張っていくと、追加の質問やポイントが出てきて、それを主要な利害関係者のところに持ち帰らなければならないことがわかりました。私たちは、各段階で追加の開発者を入れ続けることで、この問題をさらに悪化させてしまいました。これは結局、一連の循環型の議論を生み出し、タイムラインをさらに悪化させ続けました。
- 最終的には、会議やデザインレビューの間に時間がかかりすぎてしまいました。デザインの更新は1日で終わるのに、チームでレビューするのに1週間も待たされていました。これがリモートワークの一番の弊害だと思います。オフィスでは、即興のフィードバックを得るために人の肩を叩いていました。リモートで仕事をしていると、会議のスケジュールを組んだり、かなり忙しいスケジュールの中で仕事をしたりしなければなりませんでした。
だから、解決策は?全く逆のことをして、次のデザイン機能を1週間以内に完成させよう。何がいけないのでしょうか?
Design Sprint。それはまさにプロセスなり
私たちはリモートで仕事をしていたので、在宅勤務の方針に合わせて Design Sprint の方法論を少し修正しなければなりませんでした。
- すべての会議は、会議室で個人的に行うのではなく、GoToMeeting を介して行われます。
- このデザインを素早く把握するために部屋に入る必要があるキープレイヤーを把握する。私たちは、デザイナー、開発者リード、開発者のミックスに着地しました。我々はまた、日進月歩のレビューを与えるために、"上の人 "とのいくつかのフォローアップミーティングを持つことを決めました。
- チームメンバーを選ぶことで、その人たちがチームの残りの部分を代表して話すことを明確にしました。会社全体をまとめて100%の合意を得ることは不可能でしょう。ある時点では、チームのリーダーは他の人にコントロールを委譲しなければならないでしょう。
- 公式の」 Design Sprint の方法論に従って、チームはこのプロセスに40時間を費やす必要があります。現在進行中の作業と、これが「ベータ版」の取り組みであるという事実を考えると、この機能を完成させるためには1日90分という時間が必要になります。
- デザインチームは、毎日達成したいことを網羅したアウトラインをまとめました(※脚注やスケジュールのスクリーンショットを追加してください)。
- 公式な方法論を確認しましたが、私たちのためにプロセスをかなり自由にしました。
結果はどうだったか
手短に言うと...本当によくできました。
- 開発者は、設計プロセスにもっと参加したいという希望を表明しています。 Design Sprint では、初日から自分たちの考えを表現することができました。また、このプロセスでは、彼らが考えていた解決策をスケッチし、デザインする機会を与えてくれました...それがペンと紙であっても、シンプルなパワーポイントであっても。
- 私たちは、バーチャルホワイトボードとして壁画ソフトを利用することにしました。これは、ブレインストーミング中に全員が自分の考えをタイプしたり、さらに発展したものを見たいと思った項目を「スターリング」したりすることができるようにするための素晴らしい決断であったと思います。一週間を通して、グループは初日のメモやスケッチを参照し続けました。
- 1日目は予定より遅れてしまいました。1日90分というのは、このプロセスを始めるにあたり、私が一番恐れていたことでした。私は、会議がどれだけすぐに逸脱してしまうかを知っているので、簡単に1時間を失ってしまうことになります。私たちは、このような議論をできるだけ早く終わらせるように心がけていましたが、実際にはそうなってしまいました。
次回は何をするか
Design Sprint は成功しましたが、プロセスを改善するために変更できることがいくつかあります。
- 毎日、より多くの時間を割くこと。1日90分だけでは、全員の考えを完全に具現化するには十分な時間ではありませんでした。
- 理想的には、ホワイトボードやポストイット、目と目が合うような形で、直接会って行うのが良いでしょう。電話でできる限りのことはしましたが、やはり対面でのフィードバックが理想です。
- プロトタイプのフィードバックをしてくれる時間を割いてくれる顧客の具体的なグループを持っている。
まとめ
これはあなたのチームでも当てはまることなのでしょうか?私はそう思います。
HCL Software DevOps では、非常に意見の多いチームがあり、彼らの声を聞きたいと思っています。このプロセスは、それを可能にしてくれました。全員が自分たちが取り組んでいることに興奮し、エンドツーエンドのプロセスに手を貸したと感じたとき、製品は恩恵を受けることができます。それを実現するためには、日々の仕事に追われていると感じないように、時間を割き、チームに必要なリソースを与えなければなりません。しかし、最終的には、テスト可能な具体的な成果物プロトタイプができあがります...1週間の作業も悪くありません。
HCL Accelerate は、チームが世界中に分散している場合でも、オフィスで一緒に作業している場合でも、スプリントを成功させるためのお手伝いをします。チームメンバーごとに作業を整理するスイムレーンのような機能や、すでに使用しているツールと統合する機能を備えた HCL Accelerateは、DevOps パイプラインの測定、トラッキング、最適化をこれまで以上に容易にします。ここから無料でダウンロードしてください。
HCL Domino の文書削除ログ: 見つからない文書を解決する方法
2020/8/19 - 読み終える時間: 3 分
Domino Document Deletion Logging: How to Solve for Missing Documents の翻訳版です。
HCL Domino の文書削除ログ: 見つからない文書を解決する方法
2020年8月19日
著者: Jessie Jeffrey Matias / HCL
Domino の管理者として、あなたはユーザーから「この特定のメールはどこにあるのか!」と聞かれたことがあるかもしれません。Domino の古いバージョンでは、複数のユーザーが使用しているアプリケーションで重要な文書が消えてしまい、誰が、何を、いつ、どのようにして特定の文書が削除されたのかを特定する方法がない場合、長年の問題となっていました。もう心配ありません。Domino 文書の削除ロギングは、Domino V10から利用可能になった機能です。 彼らが探している文書に何が起こったのかを説明することができるようになりました。
では、どのように実装すればいいのでしょうか?それは、文字通りデータベース上でコンパクトタスクを実行するのと同じくらい簡単です。新しいコンパクトタスクのオプションで、指定したデータベースに削除された文書に関するデータをロギングできるようになります。このような機能を実現するために必要な主な要件は以下の通りです。
-
Domino V10以上を使用していること。
-
トランザクションのロギングが有効になっていること。
-
監視するデータベースに対して compact タスクを実行する。
load compact <データベースパス> -dl on "<項目のカンマ区切りリスト>"
ここで、<データベースパス>は、特定のデータベースまたはデータベースのディレクトリで、データディレクトリからの相対的なもの、例えば mail や discussion.nsf などです。
<カンマで区切られた項目のリスト> は、削除された文書を識別するのに役立つログに表示するフィールドのリストです。フィールドは、以下のタイプのいずれかでなければなりません。Text、Text_List、RFC822_Text、または Time のいずれかでなければなりません。メール文書に推奨されるフィールドは、Subject、SendTo、From、および DeliveredDate です。文書にカスタムフィールドがある場合は、それらも使用できます。
データは delete.log という削除ログファイルに記録され、サーバーの Data ディレクトリ、IBM_TECHNICAL_SUPPORT フォルダの下にあります。データベースから文書が削除されると、そのファイルにエントリが追加されます。
サーバーが再起動されると、新しい削除ログ ファイルが作成されます。古い削除ログ・ファイルは delete_<サーバ名>_yyyy_mm_dd@hh_mm_ss.log に名前が変更されます。例: delete_Server1\Renovations_2020_01_10@06_28_45.log
データベースから文書を削除すると、現在の削除ログファイルに次のデータのエントリが追加されます。このデータは、CSV 互換の形式で提供されます。
削除ログエントリのデータ一覧
文書を削除した日時
文書が削除されたデータベース: データ ディレクトリの相対値
データベースのレプリカ ID: データベース名がすべてのサーバーで同じではない場合に、データベースの複数のレプリカをログから見つけるのに役立ちます。
削除を行ったプロセス: 例:
- server
- dbmt
- replica
文書を削除したサーバー名またはユーザー名
文書削除の種類
- SOFT - 文書はゴミ箱にあります。
- HARD - スタブ削除 (ゴミ箱から文書を削除する場合など)
- RESTORE - ソフト削除後の文書の復元
削除された文書のクラス: 以下のいずれかの 16 進数で指定します。
- 0001 (文書 - NOTE_CLASS_DATA)
- 0002 (データベース文書について - NOTE_CLASS_INFO)
- 0004 (フォーム - NOTE_CLASS_FORM)
UNID: レプリカ間での一意の文書識別子
アイテム: 削除された文書のフィールド値を最大4つまで指定して、識別に役立てることができます。削除ログを有効にしたときに指定します。4 つ以上のフィールド値を指定できますが、最初に見つかった 4 つのフィールド値のみがログ エントリに表示されます。各項目には、項目名、項目値の長さ、項目値の最初の 400 文字の 3 つの部分があります。
データベース上での文書削除を監視する必要がなくなった場合は、次のコマンドを実行します。
この機能を使用する際の注意点は以下の通りです。
-
コンパクトコマンドを入力する際に、カンマで区切られた項目のリスト内にスペースを入れないこと。
-
正: load compact mail/admin.nsf -dl on "SendTo,From,DeliveredDate"
-
誤: load compact mail/admin.nsf -dl on "SendTo, From, DeliveredDate"
-
-
コマンド入力時にカンマ区切りで 4 件以上の項目を入力することができますが、削除ログファイルにはカンマ区切りの4件のみが記録されます。ただし、削除ログファイルに記録されるのはカンマ区切りの4項目のリストのみです。
詳細についてはこちらをご覧ください。
Search
Categories
- Aftermarket Cloud (2)
- AppScan (178)
- BigFix (198)
- Cloud (14)
- Cloud サービス (1)
- Collaboration (625)
- Commerce (23)
- Customer Data Platform (1)
- Data Management (3)
- DevOps (223)
- Domino (1)
- General (237)
- News (11)
- Others (4)
- SX (1)
- Total Experience (13)
- Unica (171)
- Volt MX (75)
- Workload Automation (18)
- Z (48)